문제
Pandas에서 데이터에 NaN, Inf 이 있다면 계산 시에 NaN이 나온다. 하지만 없는 데에도 나오는 경우가 있다.
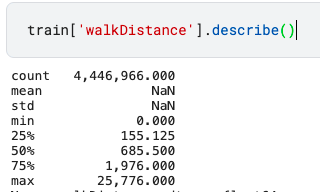
위와 같이 최소, 최대값을 확인해도 없는데 평균, 표준편차를 확인하면 NaN 나온다. 그래서 넘파이 nanmean, nanstd를 사용해 보았다.

오히려 inf 값이 나오는 것이다.
NaN값이 들어가 있으면 np.nanmean, np.nanstd는 inf값을 반환하고 inf값이 포함되면 nan을 반환한다.
원인
판다스는 기본적으로 float64, int64로 지정합니다. 뒤의 숫자는 bit크기를 의미합니다. 크기에 따라 저장하는 정보가 달라짐을 알 수 있습니다.
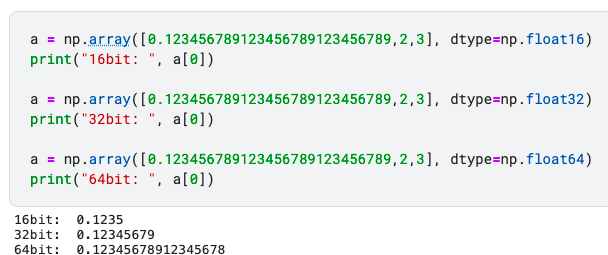
제 경우에는 메모리 사용량 줄이기 위해서 float16에 더 작은 고정된 범위로 맞추었더니 계산하면서 오버플로우가 생겨 inf값이 나오는 것이다. 그래서 일반적으로 float 32, float64를 사용한다고 합니다.
해결방법
타입 캐스팅 해주어서 오버플로우 발생하지 않도록 해주면 된다.
| dtype | character | 설명 |
| int8 | i1 | 8-bit signed integer |
| int16 | i2 | 16-bit signed integer |
| int32 | i4 | 32-bit signed integer |
| int64 | i8 | 64-bit signed integer |
| uint8 | u1 | 8-bit unsigned integer |
| uint16 | u2 | 16-bit unsigned integer |
| uint32 | u4 | 32-bit unsigned integer |
| uint64 | u8 | 64-bit unsigned integer |
| float16 | f2 | 16-bit floating-point number |
| float32 | f4 | 32-bit floating-point number |
| float64 | f8 | 64-bit floating-point number |
| float128 | f16 | 128-bit floating-point number |
| complex64 | c8 | 64-bit complex floating-point number |
| complex128 | c16 | 128-bit complex floating-point number |
| complex256 | c32 | 256-bit complex floating-point number |
| bool | ? | Boolean (True or False) |
| unicode | U | Unicode string |
| object | O | Python objects |
출처:
https://numpy.org/doc/stable/user/basics.types.html?highlight=s#overflow-errors
Data types — NumPy v1.23 Manual
Array Scalars NumPy generally returns elements of arrays as array scalars (a scalar with an associated dtype). Array scalars differ from Python scalars, but for the most part they can be used interchangeably (the primary exception is for versions of Python
numpy.org
'Data > Python' 카테고리의 다른 글
| [Google Developers] GMAIL API 사용방법 1 - 소개 (0) | 2022.11.23 |
|---|---|
| 개발자 필수 시험이 될 프로그래머스의 코딩역량인증시험 PCCP.E (3) | 2022.08.30 |
| [Python] 코랩(Colab) 한글 깨짐 현상 해결방법 (0) | 2022.07.08 |
| Python 코드 관리하기 (0) | 2022.01.12 |
| 프로그래머스[정렬] :K번째수,가장 큰 수,H-Index (0) | 2021.07.23 |