Light GBM(Light Gradient Boosting Machine)
데이터 분야로 공부하면서 Light GBM이라는 모델 이름을 들어보셨을 겁니다. 특히 캐글에서는 여러 개의 유명한 알고리즘들이 상위권에서 주로 사용되고 있습니다. 그중 하나가 Light GBM이고 이번에 Light GBM에 대한 핵심적인 특징과 설치방법, 사용방법과 파라미터와 같은 핵심만 소개하겠습니다. 그리고 사용방법을 익히고 나서 하이퍼파라미터를 과적합이나 속도 향상을 위해서 무엇을 어떻게 조절하는지를 최하단에 소개하겠습니다.
Boosting
머신러닝 앙상블 중 하나로 무작위 선택보다 성능이 약간 좋은 weak learner를 순차적으로 결합하여 높은 성능의 모델을 만들어 내는 방식입니다.
Light GBM
Gradient Boosting 프레워크로 Tree 기반 학습 알고리즘
이전의 부스팅 계열 알고리즘은 분기하기 위한 information gain을 추정하기 위해서 모든 데이터 객체와 피쳐를 스캔하기 때문에 시간이 오래 걸린다.
위의 시간이 오래걸리는 문제를 해결하기 위해서 GOSS(Gradient-based One-Side Sampling), FFB(Exclusive Feature Bundling)를 도입했다.
1. 특징
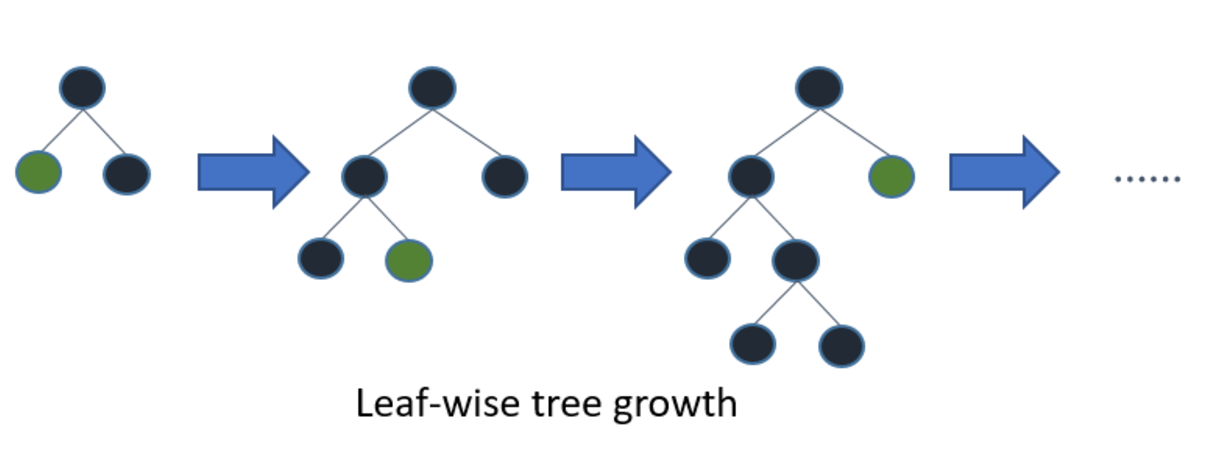
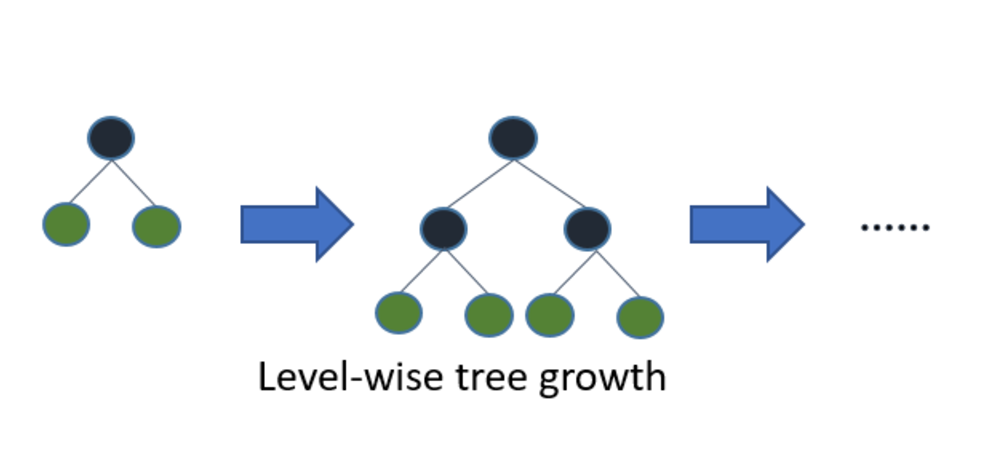
다른 Tree 기반 알고리즘과 차이점은 확장 방향입니다. 다른 트리 기반 알고리즘은 XGBoost와 같이 level-wise로 Tree가 수평적으로 확장
- leaf-wise Tree가 수직적으로 확장
- 확장하기 위해서 max delta loss를 가진 leaf를 선택
- 더 많은 loss를 줄일 수 있습니다.
장점
- 빠른 학습 속도
- 적은 메모리 사용
- 큰 스케일의 데이터를 핸들링할 수 있음
- 대비해서 높은 정확도
- GPU에서 학습 가능
- 분산, 병렬 학습 지원
이전에 사용되왔던 머신러닝 알고리즘은 요즘의 큰 사이즈의 데이터로 빠르게 학습되지 않습니다. 이름에 Light라는 말과 같이 경량화된 모델임을 이름으로부터 알 수 있습니다. 위의 3가지 특징인 빠른 학습 속도로 큰 데이터를 적은 메모리를 사용하여 학습할 수 있음에도 높은 정확도도 보여 인기를 끌었던 것입니다. 또한, 오늘날에는 GPU를 많이 사용하기 때문에 GPU를 지원하는 것으로 오늘날 인기가 많은 것입니다. 실제로 동일한 큰 데이터셋으로 학습시켰는데 XGBoost는 8시간 넘게 걸렸는데 LGBM은 약 2시간도 안 걸렸습니다. 그리고 성능도 거의 유사했습니다.
특징이 큰 데이터셋에 사용할 수 있다이면 이 의미는 작은 데이터 세트에는 적합하지 않다는 의미입니다. 모델 자체가 이미 충분히 복잡해서 큰 데이터에 적합한데 이 복잡한 모델을 작은 데이터로 학습하면 과적합되기 쉽습니다. 따라서 하이퍼파라미터 튜닝이 매우 중요합니다. 경험적으로 1만 이상 행을 갖는 데이터 사용을 권유됩니다.
Light GBM은 Light GBM이라는 프레임워크를 제공하고 있기 때문에 설치 후 학습해서 쉽게 사용할 수 있습니다. 하지만 하이퍼 파라미터가 많아서 주요 하이퍼 파라미터를 알고 사용해야 합니다.
2. 하이퍼 파라미터
max_depth: Tree의 최대 깊이. 이 파라미터는 모델 과적합을 조절하기 위해 프루닝(가지치기) 하기 위해 사용한다.
min_data_in_leaf Leaf가 가지고 있는 최소한의 레코드 수. 디폴트 값은 20으로 과적합 조절하기 위해 사용
feature_fraction Boosting이 랜덤 포레스트일 경우로 0.8
- Light GBM이 Tree를 만들 때 매번 각각의 iteration 반복에서 파라미터 중에서 80%를 랜덤 하게 선택한다.
bagging_fraction : 매번 iteration을 돌 때 사용되는 데이터의 일부를 선택하는데 트레이닝 속도를 높이고 과적합을 방지할 때 주로 사용
early_stopping_round : 속도를 향상에 도움이 됩니다. 모델은 만약 어떤 validation 데이터 중 하나의 지표가 지난 early_stopping_round 라운드에서 향상되지 않았다면 학습을 중단합니다. 지나친 iteration을 줄이는데 도움이 됩니다.
lambda : regularization으로 0에서 1 사이의 범위를 갖는다.
min_gain_to_split : 분기하기 위해 필요한 최소 gain으로 Tree에서 분기의 수를 조절할 때 사용
max_cat_group : 카테고리 수가 클 때, 과적합을 방지하는 분기 포인트
- Light GBM 알고리즘이 카테고리 그룹을 max_cat_group 그룹으로 합치고 그룹 경계선에서 분기 포인트를 찾습니다. 디폴트 값은 64입니다.
Task : train(학습), predict(예측)
application : 어떤 형태의 문제를 해결해야 하는지 정의하며 기본값은 회귀 문제
- regression: 회귀분석
- binary: 이진 분류
- multiclass: 다중 분류
boosting : 알고리즘 종류
- gdbt : Traditional Gradient Boosting Decision Tree (기본값)
- rf : Random Forest
- dart : Dropouts meet Multiple Additive Regression Trees
- goss : Gradient-based One-Side Sampling
num_boost_round : boosting iteration 수
learning_rate : 최종 결과에 대한 각각의 Tree에 영향을 미치는 변수입니다. GBM은 초기의 추정 값에서 시작하여 각각의 Tree 결과를 사용하여 추정 값을 업데이트 크기를 조절.
- 일반적 0.1, 0.001, 0.003
num_leaves : 전체 Tree의 leave 수 (기본값 31)
device :
- cpu (기본값)
- gpu
지표 파라미터
- regression과 classification을 위한 일반적인 손실 함수
regression 지표
- mae : mean absolute error
- mse : mean squared error
classification 지표
- binary_logloss : loss for binary classification
- multi_logloss : loss for multi classification
입출력 관련 하이퍼 파라미터
- 모델 관련 파라미터보다는 모델에 입력받는 형태나 출력 형태에 대해서 정의하는 것
max_bin : feature 값의 최대 bin 수
categorical_feature : 범주형 feature의 인덱스
ignore_column : 특정 칼럼을 무시한다.
save_binary : True 설정 시 데이터 세트를 바이너리 파일로 저장하면에 데이터를 읽어올 때 그 속도를 줄여줄 것입니다.
하단의 공식문서 링크에서 더 자세한 하이퍼 파라미터를 확인할 수 있습니다.
https://lightgbm.readthedocs.io/en/v3.3.2/Parameters.html
3. Light GBM 프레임워크
- 그래디언트 부스팅 프레임워크(트리 기반 학습 알고리즘)로 Python, R 모두 지원
Welcome to LightGBM's documentation! - LightGBM 3.3.2.99 documentation
3.0 설치
Mac
brew install lightgbmAnaconda
conda install -c conda-forge lightgbmVSCode
git clone --recursive <https://github.com/microsoft/LightGBM>
cd LightGBM
mkdir build
cd build
cmake -A x64 ..
cmake --build . --target ALL_BUILD --config Release
3.1 사용방법
1. 데이터 로드
- LibSVM (zero-based) / TSV / CSV 포맷의 텍스트 파일 file
- NumPy 2D array(s), pandas DataFrame, H2O DataTable’s Frame, SciPy sparse matrix
- LightGBM binary file
- LightGBM Sequence object(s)
데이터는 데이터셋 객체에 저장된다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.cross_validation import train_test_split
import lightgbm as lgb
df = pd.read_csv('...input/data.csv')
X = df.iloc[:, [2, 3]].values
y = df.iloc[:, 4].values
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 42)
x_train = lgb.Dataset(x_train, label=y_train)
범주형인 경우 피쳐 이름 설정 가능
e, g, feature_name=['c1', 'c2', 'c3'], categorical_feature=['c3']
3. 하이퍼 파라미터 설정
- 하이퍼 파라미터를 딕셔너리 형태로 넣어줘야 합니다.
- 바로 딕셔너리에 쓸 수도 있고 딕셔너리 키, 값 설정하거나 값을 리스트 형태로 여러 개 설정 가능
param = {'num_leaves': 31, 'objective': 'binary'}
param['metric'] = 'auc'
param['metric'] = ['auc', 'binary_logloss']
변환된 데이터 세트 생성 이후에, 파라미터와 그 값으로 구성된 Python Dictionary 파이썬 딕셔너리를 생성했습니다. 모델의 정확도는 설정된 파라미터 값에 전적으로 달려 있습니다.
4. 모델 빌드
4.1 분류
- 예시는 이진 분류로 num_leaves 10인 작은 데이터
params = {}
params['learning_rate'] = 0.003
params['boosting_type'] = 'gbdt'
params['objective'] = 'binary'
params['metric'] = 'binary_logloss'
params['sub_feature'] = 0.5
params['num_leaves'] = 10
params['min_data'] = 50
params['max_depth'] = 10
clf = lgb.train(params, x_train, 100)
4.2 회귀
params= {"objective" : "regression", "metric" : "mae", 'n_estimators':20000, 'early_stopping_rounds':200,
"num_leaves" : 31, "learning_rate" : 0.05, "bagging_fraction" : 0.7,
"bagging_seed" : 0, "num_threads" : 4,"colsample_bytree" : 0.7,
'min_data_in_leaf':1900, 'min_split_gain':0.00011,'lambda_l2':9
}
5. 모델 예측
싸이킷런과 동일한 형태로 predict 메서드를 제공하고 Numpy Array형식으로 출력합니다.
클래스는 확률(sklearn의 predict_proba와 동일), 회귀는 예측값
y_pred=clf.predict(x_test)

6. 조기종료(early stopping)
최적의 부스팅 라운드(boosting rounds) 수를 찾기 위해서 사용하며 검증 데이터가 더 이상 나아지지 않으면 중간에 종료하게 됩니다. 정해진 early_stopping_rounds
lgb.Dataset('validation.svm', reference=train_data)
- valid_sets
- early_stopping_rounds
bst = lgb.train(param, train_data, num_round, valid_sets=valid_sets, early_stopping_rounds=5)조기 종료를 통해서 가장 높은 성능을 자랑한 이터레이션 인덱스가 best_iteration에 저장됩니다. 기본적으로 2가지 지표를 최소, 최대화하는데 first_metric_only=True 통해서 조정 가능하다.
ypred = bst.predict(data, num_iteration=bst.best_iteration)
bst.save_model('model.txt', num_iteration=bst.best_iteration)
8. k-fold 교차검증 데이터셋
학습 데이터를 몇 개로 나누어 교차 검증할 것인지 지정 가능
lgb.cv(param, train_data, num_round, nfold=5)
이외 지표를 테스트하고 싶으면 싸이킷런 사용하면 됩니다.
4. 파라미터 튜닝
어떤 값이 최적의 파라미터 값 일지 결정하기 위해 조정합니다. 파라미터 튜닝을 하지 않으면 과적합 되기 쉽습니다.
leaf-wise 기반 트리 성장 알고리즘(leaf-wise tree growth algorithm)의 쥬요 튜닝 대상
이 3가지는 과적합 제한하는 데 주로 사용
- num_leaves 모델 복잡성 제한
- 이론적으로는 num_leaves=2^ max_depth
- 동일한 num_leaves로는 leaf-wise 기반 트리가 더 깊어지기 때문에 과적합되기 쉽다. num_leaves < 2^ max_depth
- min_data_in_leaf 깊이 확장 제한
- max_depth 깊이 제한
속도 향상
- 컴퓨터 리소스 추가하기
- bagging_fraction, baggin_freq을 설정하여 bagging을 적용
- feature_fraction 설정하여 feature sub-sampling
- 작은 max_bin 값을 사용
- save_binary 데이터 용량 줄이기
- cli에서만 가능
- 이미 학습 시에 저장된 정보가 있어 로드 시에 다시 처리할 필요가 없음
- parallel learning 병렬 학습을 적용
- 더 적은 데이터 사용하기 위해 배경으로 조정
- 각 이터레이션마다 몇 번의 중복 추출을 하고 학습 데이터의 얼마나 가져올 것인지 설정하여 비율이 준다면 더 적은 데이터를 사용하기 때문에 속도 빨란 진다.
- {"bagging_freq": 5, "bagging_fraction": 0.75}
- 깊이가 얕은 트리 (shallower Tree)
- max_depth, num_leaves 줄이기
- min_gain_to_split, min_data_in_leaf, min_sum_hessian_in_leaf 늘리기
- 트리 수 줄이기
- num_iterations 줄이기
- 조기 종료 사용하기
- split 줄이기(매 트리의 노드 수를 조정)
- 데이터셋 min_data_in_bin 늘리기
- 데이터셋 max_bin , max_bin_by_feature 줄이기
- feature_fraction, max_cat_threshold 줄이기
정확도 향상
- 큰 max_bin 값을 사용( 속도가 느려질 수 있습니다)
- 작은 learning_rate 값을 큰 num_iterations 값과 함께 사용
- 큰 num_leaves 값을 사용 ( 과적합 발생할 수도 있습니다)
- 더 큰 트레이닝 데이터를 사용
- dart를 사용
- 범주형 feature를 사용하십시오
과적합(overfitting) 최소화
- 작은 max_bin , num_leaves값
- min_data_in_leaf , min_sum_hessian_in_leaf 사용
- bagging_fraction , bagging_freq을 사용하여 bagging을 적용
- feature_fraction을 설정하여 feature sub-sampling
- regularization (정규화) : lambda_l1, lambda_l2 , min_gain_to_split
- max_depth를 설정해 Deep Tree 가 만들어지는 것을 방지
출처:
Welcome to LightGBM's documentation! - LightGBM 3.3.2.99 documentation
'Data > AI' 카테고리의 다른 글
| [회고] AI 프로젝트 2. 실시간 이미지 합성 서비스- 프로그래밍도 모르는 내가 딥러닝? (0) | 2025.03.22 |
|---|---|
| [회고] AI 프로젝트 1. OTT 추천 서비스(데이터 기반 서비스 기획) (0) | 2024.11.13 |
| [MLOps] A Chat with Andrew on MLOps: From Model-centric to Data-centric AI(모델 중심 (0) | 2022.03.21 |
| 추천 시스템(Recommender System)- 3. Collaborative Filtering(협업 필터링) (0) | 2022.02.06 |
| 추천 시스템(Recommender System)- 2. Content-based Filtering(콘텐츠 기반 필터링) (0) | 2022.02.05 |