A Chat with Andrew on MLOps: From Model-centric to Data-centric AI
Model-centric vs Data-centric
| 모델 중심의 생각(Model centric view) | 데이터 중심의 생각(Data centric view) |
| - 수집가능한 데이터를 모으고 데이터의 노이즈를 잘 이겨내는 좋은 모델을 만들어 낸다. | - 데이터의 일관성이 제일 중요하다. 데이터의 질을 유지할 수있는 툴 사용하면 다양한 모델들이 좋은 성능을 낼 것이다. - 데이터가 적은 경우 중요하다. |
| - 모델을 계속해서 개선해냄 | - 시스템화하며 계속해서 데이터를 개선해낸다.(데이터 추가수집,data augmentation(데이터 증강),라벨링 개선 |
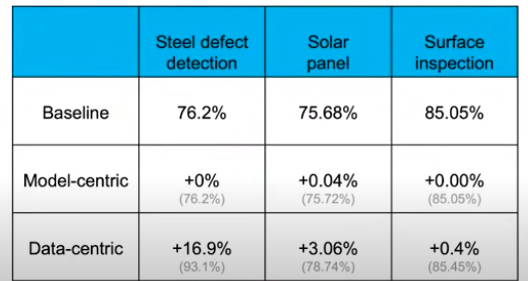
위의 테이블에서 여러 도메인에서 모델 중심과 데이터 중심의 AI로 했을때 성능의 차이를 비교하고 있다. 철강 결함 탐지, 태양광 패널, 표면 검사등의 작업에서 데이터 중심인 경우 모델 중심인 경우보다 성능 향상이 더욱 컸다.
- 모델 튜닝보다는 데이터의 질이 더 중요하다.

- 이미지 데이터셋을 라벨링 하라고 하면 각 라벨러마다 다르게 라벨링 하는 것을 알 수 있다. 위의 이미지처럼 객체마다 바운딩 박스를 그릴 수도 있고 아니면 모든 객체를 하나의 바운딩 박스로 라벨링 할 수 도 있다.
- 해결책:
- 라벨러들에게 이미지 라벨링하도록 시켜보고 라벨링 일관성을 비교해보자.
- 각 라벨러들이 다르게 라벨링한 부분의 라벨링 가이드라인을 수정하자.
- annotation의 일관성: 명확한 컨벤션에 따라 노이즈 제거, 처리나라벨링 방식을 맞춰야 한다.
데이터와 모델
캐글의 데이터셋의 크기는 보통 1k~10k이지만 모든 도메인에서 이와 같은 양의 데이터를 모을 수 있지 않다. 하지만 현실에서는 모으기 쉽지 않다.
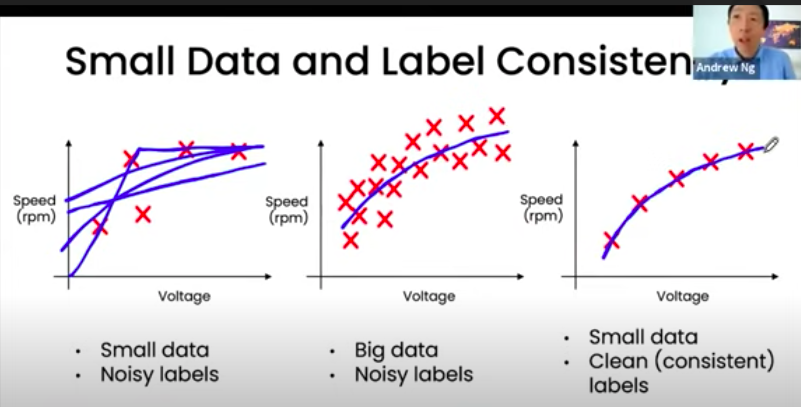
데이터의 양이 적은데 노이즈가 많으면 모델의 성능에 영향을 준다. 하지만 노이즈가 많더라도 데이터가 많거나 데이터가 적더라도 잘 정제되어 있다면 모델은 잘 추정해내는 것을 알 수 있다.
빅데이터의 문제 : 롱테일( 특정 20%가 전체의 80%를 차지하고 나머지 80%가 20%를 차지한다.) 모두 동일하게 데이터 양을 맞춰 수집할 수가 없다.(웹 서치, 자율주행, 추천 시스템)

위의 그래프를 보면 데이터에서 노이즈를 제거하는 경우가 학습 데이터를 약 2.5배 정도 늘리는 거와 비슷한 성능이 나온다.( 각 도메인, 데이터, 모델마다 상이함)
- 양 << 질 : 데이터의 양을 늘리는 것보다는 데이터의 퀄리티를 늘리는 쪽이 더 효과적이다.
MLOps: Making it Systematic!

위의 그림은 머신러닝 프로젝트의 라이프사이클을 보여주고 있으며 특히 프로덕션단계에서의 데이터의 중요성에 대해서 이야기하고 있다. 시스템화하기 위해서 MLOps가 필요한 이유다. 지속적으로 시스템을 통해 들어오는 데이터 수집, 분석해서 다시 모델에 재학습을 하여 모델을 개선시켜야한다. MLOps에서는 ML엔지니어가 머신러닝 프로젝트의 라이프 사이클 모든 단계에서 계속해서 일관성 있는 양질의 데이터를 가질 수 있도록 도와줘야 한다.
Error Analysis : 알고리즘이 잘 학습하지 못하는 데이터 타입을 확인한다.(e.g. speech recognition의 학습에 사용될 데이터에서 자동차 소음이 깔려 있는 경우)
- input X 바꾸는 경우: 데이터 수집, 증강, 생성
- input y 바꾸는 경우: 데이터의 라벨의 일관성을 지키기
- 데이터 수집 단계 : 데이터를 어떻게 수집하고 정의할까?
- 모델 학습 단계: 모델의 성능을 개선시키기 위해서 어떻게 데이터를 바꿔야 할까?
- 프로덕션 단계: what data do i need to track concept drift /data drift?
좋은 데이터란...
- 데이터의 라벨에 대한 정의가 명확하다
- 데이터의 중요한 케이스만 커버한다.
- 프로덕션 데이터로부터 주기적으로 피드백을 받는다.(distribution covers data drift& concept drift)
- 적당한 사이즈를 갖는다.
아직 MLOps라는 콘셉트를 접한 지 얼마 되지 않아 내용이 부족할 수 있어 이후에 더 추가 보충할 예정이다!(예. CT 하는 경우 data drift, concept drift발생)
'Data > AI' 카테고리의 다른 글
| [회고] AI 프로젝트 1. OTT 추천 서비스(데이터 기반 서비스 기획) (0) | 2024.11.13 |
|---|---|
| Light GBM 설명(특징,하이퍼파라미터,설치, 사용방법) (0) | 2022.08.02 |
| 추천 시스템(Recommender System)- 3. Collaborative Filtering(협업 필터링) (0) | 2022.02.06 |
| 추천 시스템(Recommender System)- 2. Content-based Filtering(콘텐츠 기반 필터링) (0) | 2022.02.05 |
| 추천 시스템(Recommender System)- 1. 개요 (0) | 2022.02.04 |