1.1 데이터를 지식으로 바꾸는 지능적인 시스템 구축
머신러닝,딥러닝, 인공지능(AI) 모두들 뉴스에서 많이 들어 보았을 것입니다. 최근에 은퇴한 프로기사 이세돌 씨 께서 한돌(NHN)에 패배하고 과거에 AlphaGo에게 패배하게 되면서 인공지능의 발전과 무궁한 가능성 때문에 큰 주목을 받게 되었습니다. 이외에도 앞의 세 가지 단어는 자주 synonym으로 쓰이는 경우가 많지만 딥러닝이 가장 하위 카테고리에 속하게 됩니다.

위의 그래프처럼 Artificial Inteligence (인공지능)는 새로운 개념이 아닌 이전 부터존재하는 학문으로 이것의 정의는 John McCarthy 의 'thinking machine'에서 현대에 와서는 기계가 인간의 지능을 어떻게 구현해 내는지에 대한 컴퓨터과학(computer Science, CS)의 한 분야로 정의되어졌다.
머신러닝은 데이터에서 효율적으로 지식을 추출하여 예측하는 자기 학습 알고리즘과 관련된 인공지능의 하위분야로 웹에서 연관 검색 엔진, 음성 /이미지 인식 등이 있습니다.
1.2 머신 러닝 종류
- 지도 학습(Supervised Learning)
- 비지도 학습(Unsupervised Learning)
- 강화 학습(Reinforcement Learning)
아마 처음 접하신 분들은 위와 같은 단어를 많이 들어 보았지만 정확한 정의에 대해서는 어색하게 느껴질 것입니다. 먼저 '머신러닝(machine learning)'은 기계가 학습한다고 직역해보고 나서 다음 세 가지 종류를 생각해보면 기계가 학습을 할 때 누군가의 지도하에 학습하거나 지도 없이 스스로 학습으로 주로 두 가지 방법으로 볼 수 있습니다.
1.2.1) 지도학습은 label 된 데이터(정답 ground thruth 이 주어진 데이터)를 주어 학습시키고 label이 없는 데이터를 주고 얼마나 예측을 잘하는지 모델을 검증하는 것입니다. 분류와 회귀의 차이는 출력(output) 데이터가 수치형/연속적인 값(회귀)인지 아니면 범주형/이산형 값(분류) 인지에 따라 나누어지게 됩니다. 다음과 같은 값을 구하기 위해서는 수식/규칙을 통해 최적의 해를 구하게 됩니다.
- 분류(Classification): 분류 범주의 개수에 따라 이진(binary classification)과 다중(multi-class classificaiton) 분류로 나뉨.
- 회귀 (Regression): 입력/설명/독립변수(x)와 출력/반응 변수(y) 간의 함수적 관계가 선형이냐 비선형이냐에 따라 나뉘게 된다. 선형 회귀에서는 x, y가 주어졌을 때 제곱합(Sum of Squared Error, SSE)이 최소화되는 기울기와 절편 값을 구하여 출력 값 y를 예측.
1.2.2) 비지도 학습
- 군집(Clustering) : 어떠한 유사성을 바탕으로 군집으로 나눔. 예. 소비자 군집화
- 차원 축소(dimentionality reduction) : 고차원(high dimension)의 데이터를 저차원으로 바꾸는 기법으로 과적합(overfitting)을 방지한다. 예. 주성분 분석(Principal Component Analysis, PCA)
1.2.3) 강화 학습
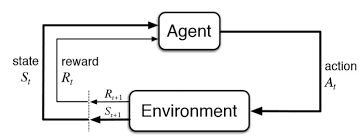
아마 크게 와 닿지 않을 것입니다. 이 책에서는 다루지 않지만 간단히 정의를 집고 넘어가겠습니다. 강화 학습은 행동 심리학으로부터 나왔습니다. 어떠한 환경에서 정의된 에이전트가 현재의 상태를 인식(상호작용)하여, 선택 가능한 행동들 중 보상을 최대화하는 행동을 선택하는 방법이며 Markov decision process (MDP)라는 확률 모델로 표현되며 이보다 더 자세한 내용은 따로 다루도록 하겠습니다. 위의 알파고나 한돌은 승리라는 보상을 바탕으로 강화학습을 사용하였습니다.
1.3 기본 용어와 표기법 소개
- 데이터셋의 가로축 :행(n개)은 각 n개의 샘플 값을 가짐.
- 데이터셋의 세로축 :열(m개)은 각 샘플들의 속성에 관한 값들을 가짐
- 예. 학생에 대한 데이터가 n X m개 있다면 각 n명의 학생에 대한 정보는 행이 되고 이 한 학생에 대한 학번, 성별, 연령 등에 대한 특성은 m개의 열이 된다.
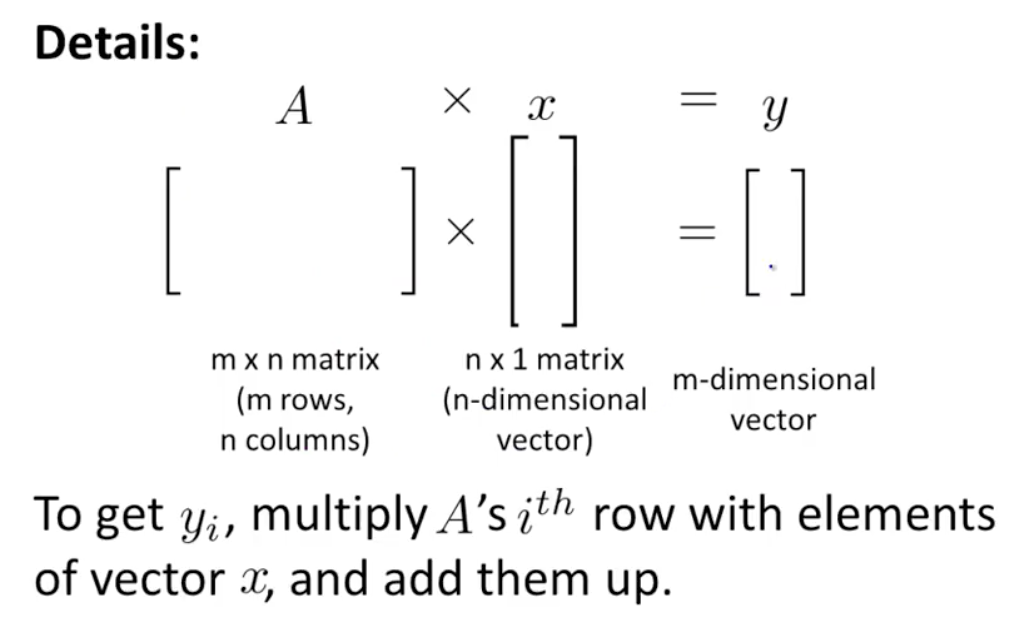
- 매트릭스(Matrix): 굵은 대문자 X
- 벡터(vector): 굵은 소문자 x
- x : column vector (n*1 dimension)
- x^t: row vector (1*m dimension) x의 전치
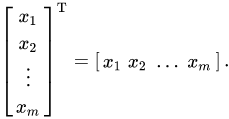
*특히 선형대수학(Linear Algebra)의 개념이 중요합니다.
1.4 머신 러닝 시스템 구축 로드맵
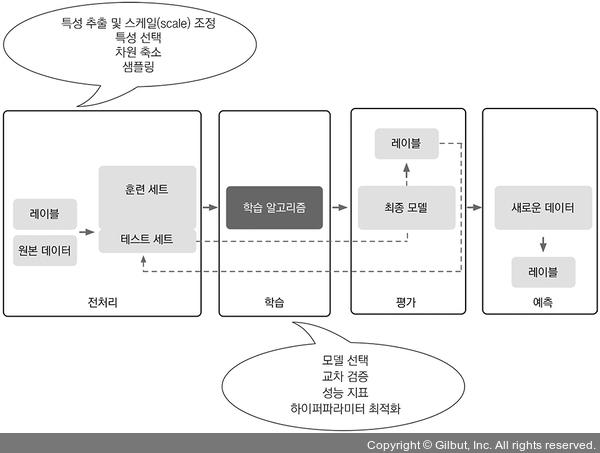
1)전처리
- 스케일 조정: 가장 중요하고 가장 많은 시간이 소요되는 전처리 단계로 수치형 데이터를 사용 시 스케일 변환(정규분포화)하여 비교
- 차원 축소: 상관관계가 높으면 다중공선성의 문제가 생기어 추가적인 변수의 설명력이 줄어들게 되어 차원 축소를 통해서 이를 줄일 수 있다.
2) 예측 모델 훈련과 선택
예측을 위해 트레이닝 데이터에 훈련된 모델들 중 어떠한 측도에 따라 성능을 비교하여 테스팅 데이터에 검증하게 됩니다. 검증에도 여러 방법이 있습니다.(Bootstraping, hold-out , k-folds cross validation, random subsampling...) 또한, 각 모델의 성능을 조정하기 위한 파라미터를 최적화 기법을 사용합니다.
3) 예측
다음 검증 방법에 따라서 train data set& test(검증) data set으로 나눈 후 훈련 데이터에서 최적인 모델을 사용하여 테스트에서 검증을 하여 예측의 정확성을 검증하게 됩니다. 이와 같이 하는 이유는 학습한 데이터로 예측을 하게 된다면 학습한 기계는 이미 있는 데이터를 기반으로 하여 학습한 데이터에서만 정확도가 과하게 높게 나오는 과적합 현상이 생기게 됩니다. 문제은행에서 시험이 나오는 것과 배운 것을 바탕으로 응용문제가 나왔을 때 문제은행에서 나온 문제와 답을 맞힐 확률이 확연하게 높은 것을 예로 들 수 있습니다.
Summary
- AI ⊃ML ⊃DL
- ML 종류
- 지도학습 : 회귀, 분류
- 비지도학습 : 군집, 차원 축소
- 강화학습
- 머신러닝 구축 로드맵 : 전처리 ,학습,평가,예측
P.S. 강화학습 부분은 아직 낯선 개념이 많아 따로 공부 해야할 듯..
[Data Science/ML] - 머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
<머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 Python Machine Learning By Example, 2/E : Implement machine learning algorithms and techniques to build intelligent systems(Paperback, 2nd Edition)..
potato-potahto.tistory.com
Reference
https://brunch.co.kr/@gdhan/10
https://blogs.nvidia.co.kr/2016/08/03/difference_ai_learning_machinelearning/
'Data > ML' 카테고리의 다른 글
| 5.차원축소를 이용한 데이터 압축 (0) | 2021.06.13 |
|---|---|
| 4. 데이터 전처리 (0) | 2021.06.12 |
| 3.사이킷런을 타고 떠나는 머신 러닝 분류 모델 투어 (0) | 2021.06.11 |
| 2. 간단한 분류 알고리즘 훈련 (0) | 2021.06.09 |
| 머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차 (0) | 2021.06.08 |