1. 누락된 데이터 (Not a Number, NaN) , NULL(모르는 값))
- 원인 : 데이터 수집 과정 오류, 측정 방법 적용 불가
- 빈 값(blank), 예약된 문자열로 대체
특히 수치 계산에서 누락데이터는 계산 불가한 경우도 있어 처리 필요.
- 식별 :
- isnull.sum() null값인 경우 boolean 으로 리턴하여 True값 총 갯수 리턴(누락값 갯수)
- 처리
- 특정 행/열 제외
- :( 제거시 필요한 중요한 정보 잃음
- dropna(axis= 0(행),1(열),how='all', thresh= , subset[ '열이름' ] )
- axis=0 해당 행제거, 1 해당 열제거 (Default: axis= 0)
- how='all' 모든 값이 NaN인 행 제거
- thresh= 임계값(실수, threshold) 각 행/열에 NaN이 아닌 값의 갯수가 임계값
- 예.thresh=5 인경우 NaN아닌 값들이 4개인경우 해당 행/열 제거
- 평균(mean), 중앙값(median),최빈값(Mode)으로 누락값 대체
- fillna([ 열].mean(), inplace=True)
- 보간(interpolation) 기법: 점 사이를 이용하여 추정함수 도출하여 값들을 추정
- 선형보간(1차), 2차 보간,Newton보간 : n+1개의 데이터를 n차식 추정함수 이용하여 추정값 도출
- sklearn.impute의 SimpleImputer(missing_values=np.nan, strategy = )
- strategy : mean(평균), median(중앙값), most_frequents(최빈값),constant(지정값)
- fillna([ 열].mean(), inplace=True)
- 특정 행/열 제외
2. 범주형 데이터 다루기
범주형/질적 데이터
- 명목형: 범주
- 순거가 없는 특성 :순서에 의미가 없음 예. 색상, 국가, 혈액형
- 원-핫 인코딩(one-hot encoding): 각 고유 값에 dummy variagble 추가함
- 예. red = [1,0, ... ,0] , blue= [0,1, ... ,0]
- 원-핫 인코딩(one-hot encoding): 각 고유 값에 dummy variagble 추가함
- 순거가 없는 특성 :순서에 의미가 없음 예. 색상, 국가, 혈액형
- 순서형: 범주, 순위(순서)
- 순서가 있는 특성 : 순서/순위에 의미 있음 예. 학점 A > B> C >F
- 매핑함수이용 문자열을 정수값으로 변환함(특성간의 산술적 차이 알고있음을 가정)
- 예.사이즈 S=1, M=2,L=3 ; 매핑함수 : L= M+1 =S+2
- 매핑함수이용 문자열을 정수값으로 변환함(특성간의 산술적 차이 알고있음을 가정)
- 순서가 있는 특성 : 순서/순위에 의미 있음 예. 학점 A > B> C >F
클래스 레이블 인코딩
- Label Encoder 순서 없는 1차원 배열
- Columntransformer :열 마다 변환
- OrdinalEncoder :범주형- >수치형 변환
3. 데이터 분할
지도학습에서 훈련데이터를 검정하기 위해서 학습되지 않은 데이터 사용을 위해서 데이터 분할을 함
분할 비율: 트레인 비율이 높으면 일반화 오차에 대한 추정 부정확,
- 일반적 0.6:0.4, 0.7:0.3, 0.8:0.2
- 대용량 : 0.9: 0.1
4. 특성 스케일 맞추기
최적화 알고리즘(예. 경사하강법) 성능 향상
수치형 특성에서 스케일이 큰 특성의 가중치가 커짐
- 정규화(normalization): 스케일을 [0,1]범위 내로 변환(정규분포,경사하강법,이상치 영향 축소화)
- 최소-최대 스케일링(min-max scailing)

- 표준화(Standardization): 서로 다른 모수값(평균, 표준편차)을 가진 정규분포를 가진 집단들을 서로 비교하기 위해 정규분포를 표준화함(Z-score)
- 각 관측값이 평균 0을 기준으로 얼마나 떨어졌는지 알수 있음.
- 관측값에서 평균을 빼면 분산이 되고 표준편차로 나누어 준것으로 값은 평균=0, 표준편차=1 인 표준정규 분포가 됨.


5. 유용한 특성 선택
과대적합(Overfitting): 훈련된 모델이 훈련 데이터에서 실제 데이터에서보다 성능이 크게나와 일반화가 떨어질때를 가리킴
- 데이터 수집
- 규제를 통한 복잡도 제한
- 파라미터 개수가 적은 간단한 모델 선택(차원 축소)
모델 복잡도 제한을 위한 L1, L2 규제
가중치 규제: 과대적합,과소적합 해결하는 방법 중 하나, 모델의 일반화 성능 향상
L1 규제(L1 regularization): 개별 가중치 값을 절대값으로 제한
- 희소한 특성 벡터 생성( 특성 가중치 =0) : 관련 없는 특성이 많은 고차원 데이터셋,적은 특성의 가중치 0 으로 변환
- L1 페널티: 가중치 절댓값의 합(다이아몬드 모양의 제한 범위


(최적점: w1=0: 비용 함수의 등고선이 L1 다이아몬드가 접하는 지점(축에 가깝게 위치할 가능성 높음)
L2 규제(L2 regularization) :개별 가중치 값을 제곱값으로 제한, 모델 복잡도 줄임
- 패널티 항 (Penalty term) 추가 : 규제가 없는 비용 함수로 훈련한 모델에 비해 가중치 값을 아주 작게 만드는 효과

제곱 오차합(SSE) 비용 함수= 구 모양,
훈련 데이터에서 비용 함수를 최소화하는 가중치 값의 조합(두 개의 가중치 값 w1과 w2에 대한 볼록한 비용 함수의 등고선의 중심 ). 가중치 평면에 투영된 복록 비용함수의 등고선규제를 더 작은 가중치를 얻기 위해 비용 함수에 추가하는 페널티 항. (큰 가중치를 제한)
규제 파라미터 λ: 규제의 강도를 크게 하면 가중치가 0에 가까워지고 훈련 데이터에 대한 모델 의존성은 감소
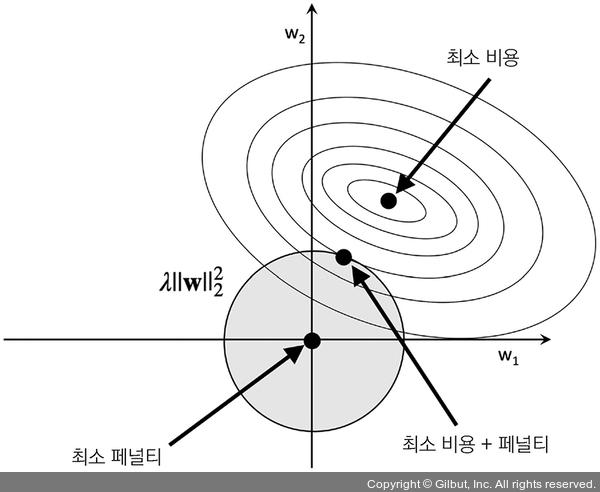
이차식 L2 규제 항: 회색 원, 가중치 값은 규제 예산을 초과 불가. 가중치 값의 조합이 회색 공 바깥에 놓일 수 없습니다.
최적: L2 회색 공(L2 ball)과 규제가 없는 비용 함수의 등고선이 만나는 지점 규제 파라미터λ가 커질수록 페널티 비용이 빠르게 증가하여 L2 공을 작게 만듭니다. 예. 규제 파라미터를 무한대로 증가, 가중치 값이 L2 공의 중심인 0이 될 것입니다. 이 예시에서 중요한 핵심을 정리하면 우리의 목표는 규제가 없는 비용과 페널티 항의 합을 최소화하는 것입니다. 이는 모델을 학습할 만한 충분한 훈련 데이터가 없을 때 편향을 추가하여 모델을 간단하게 만듦으로써 분산을 줄이는 것으로 해석할 수 있습니다.
특성 선택을 통한 차원 축소 (규제 없는 모델 유용)
- 특성 추출(Feature Extraction): 모든 원 특성들을 사용하여 새로운 특성으로 만듦(선형,비선형 결합) < > ch6.
- 특성 선택(Feature Selection): 최적화(optimizaiton)문제를 통해 일부를 선택
- 1)순차 특성 선택(Sequential Feature Selection) 알고리즘
- 탐욕적 탐색 알고리즘(Greedy search algorithm):조합 탐색 문제의 각 단계에서 국부적 최적의 선택(차선책)
- 초기 차원의 특성공간을 M<N 인 M 차원의 특성 부분 공간으로 축소
- 가장 관련이 높은 특성 부분 집합을 자동으로 선택
- 잡음 제거통해 계산 효율성 증가
- 모델 일반화 오차 줄임
- 비수치 특성에 적합
- 유의미한 규칙들을 분류기에서 추출( 측정 단위 변화 방지)
- 순차 전진 선택(Sequential Forward Selection,SFS):
- M=1개의 특성 선택으로 시작
- i=1...N으로 시작하여 M+i개의 특성의 조합에서 가장 최대화 하는 특성 집합 선택
- 사전에 지정한 특성 개수 도달시 종료
- 순차 후진 선택(Sequential Backward Selection,SBS):
- M=N, N:전체 특성 공간 Xn의 차원(모든 특성의 갯수)
- 조건 x= argmax J(Xk-x)최대화하는 특성 x결정
- 특성 집합에서 가장 안좋은 특성 제거
- M개를 목표를 하는 특성 개수도달시 종료 or 2단계로 돌아감
- 순차 전진 선택(Sequential Forward Selection,SFS):
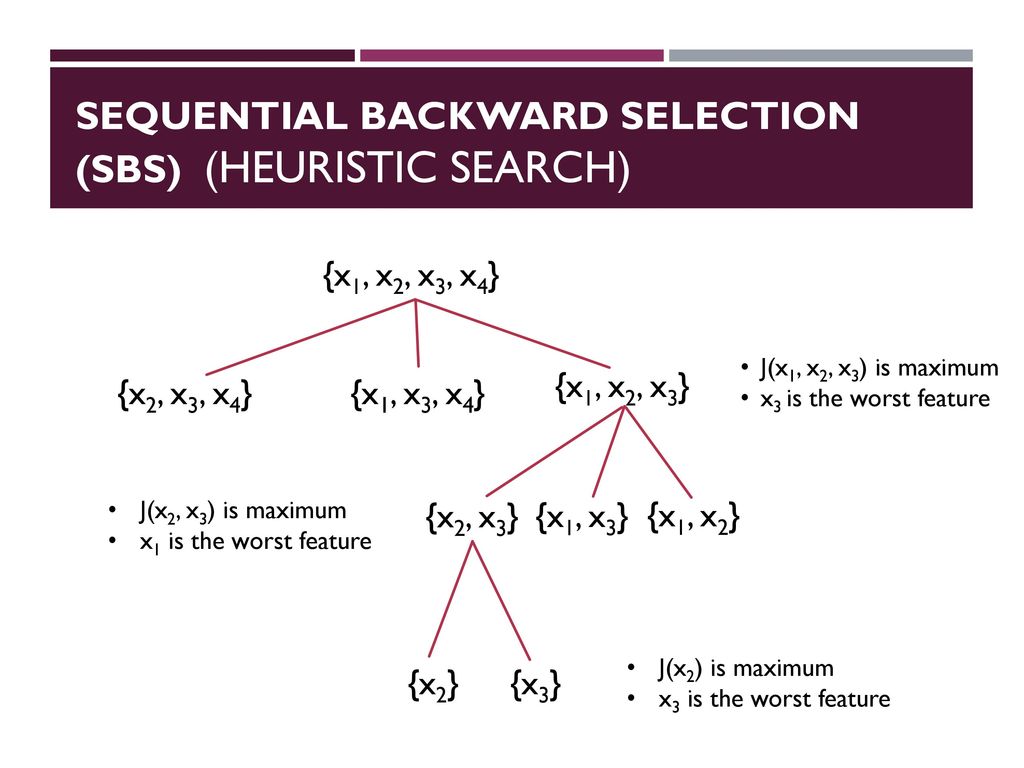
계산 효율성을 향상하기 위해 모델 성능을 가능한 적게 희생하면서 초기 특성의 부분 공간으로 차원을 축소합니다.
6. 랜덤포레스트의 특성 중요도 사용
Feature Importance: 특성들 중 상대적 중요도(비율)
앙상블에 참여한 모든 결정 트리에서 계산한 평균적인 불순도 감소를 기반으로 특성 중요도를 측정
* 트리기반은 정규화,표준화 불필요
*다중공선성: 높은 상관관계,변수간의 중요도 차이 큰 경우
wine Dataset (178 * 14)

import pandas as pd
import numpy as np
df_wine = pd.read_csv('https://archive.ics.uci.edu/'
'ml/machine-learning-databases/wine/wine.data',
header=None)
# df_wine = pd.read_csv('wine.data', header=None)
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
print('클래스 레이블', np.unique(df_wine['Class label']))
df_wine.head()
from sklearn.model_selection import train_test_split
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.3,
random_state=0,
stratify=y)
print("X_train: ",X_train.shape,"X_test: ",X_test.shape
,"y_train: ",y_train.shape, "y_train: ",y_test.shape)
X_train: (124, 13) X_test: (54, 13) y_train: (124,) y_train: (54,)
y에는 클래스 레이블을 저장하고 X에는 레이블 제외한 모든 데이터 저장한 후 각 0.3으로 나눔
124:54= 7:3으로 분할
요약
- 누락된 데이터 처리 :제거, 대체(보간법 이용)
- 범주형 데이터 처리(순서 유무)
- 데이터 분할 : 훈련 & 테스트 세트
- 특성 스케일 맞추기: 표준화, 정규화
- 유용한 특성 선택 : 가중치 규제 (L1,L2), 순차 특성 선택 ,랜덤포레스트의 특성 중요도 사용
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
<머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 Python Machine Learning By Example, 2/E : Implement machine learning algorithms and techniques to build intelligent systems(Paperback, 2nd Edition)..
potato-potahto.tistory.com
Reference
'Data > ML' 카테고리의 다른 글
| 6. 모델 평가와 하이퍼파라미터 튜닝(미세조정) (0) | 2021.06.14 |
|---|---|
| 5.차원축소를 이용한 데이터 압축 (0) | 2021.06.13 |
| 3.사이킷런을 타고 떠나는 머신 러닝 분류 모델 투어 (0) | 2021.06.11 |
| 2. 간단한 분류 알고리즘 훈련 (0) | 2021.06.09 |
| 머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차 (0) | 2021.06.08 |