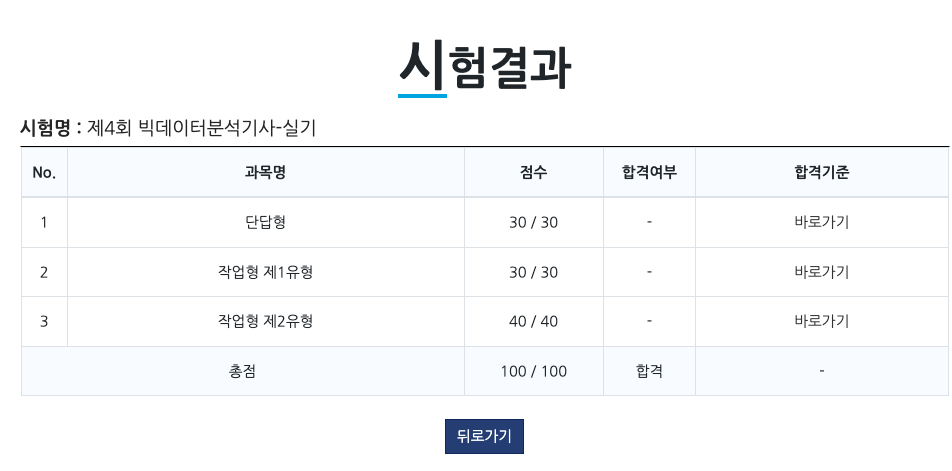
다행히 빅데이터 분석 기사 합격후기로 돌아왔습니다. 저는 실기 만점 받고 합격하였습니다. 제4회 빅데이터 분석기사 실기가 시험일로부터 2주 뒤 오후 3시에 가채점 결과 발표되었습니다. 가채점 이후 1주 뒤에 복수 답안이나 재채점 해서 최종 합격이 정해지게 됩니다.
빅데이터분석기사 실기 만점 합격 후기
1. 느낀 점
실기 2는 대부분 만점 받은 거 보니 후하게 주었습니다. 문제마다 주어진 평가지표의 구간에 따라 점수를 매기는데 4회에서 4개 클래스 '다중 분류' 문제 validation set에서 macro f-1 score 0.5 넘겨서 만점 받았습니다 그리고 테스트 데이터를 학습한 모델로 예측 결과 제출 시 index=False 하지 않아도 4회 차에서는 맞다고 해주었습니다. 직접 하면서 느낀 점은 빅데이터 분석기사 자격증을 취득했다는 것으로 실효성이 크지 않다는 것입니다. 실제로 업무 할 정도는 아니고 입문 정도로 봅니다. 필답, 실기 1,2 유형 모두 난도가 높지 않습니다. 실제로 실기 합격자들 후기를 보니 실기 2는 웬만하면 만점 가까이 주었습니다. 자격증은 그 과정에서의 노력들이 중요하다고 생각하며 공부하는 김에 스스로 테스트용으로 추천드립니다. 그리고 준비하시는 회사에서 우대나 가산점을 준다면 충분히 효용성 있습니다.
2. 공부 방법
합격보다는 고득점을 받는 것을 목표로 공부했습니다. 매일 감 잃지 않기 위해서 단답형, 작업형 1,2 모든 파트를 골고루 분배해서 매일 반복해서 공부했습니다. 그럼에도 가장 많이 시간을 투자했던 파트는 단답형과 작업형 1입니다. 작업형 2는 어느 정도 예상이 가지만 단답형과 작업형 1은 아니기 때문입니다.
2.1 단답형
아직까지 기술, 알고리즘 이름 위주로 나오기 때문에 빅데이터 분석기사 교재 필기와 실기를 기반으로 큰 틀과 중요한 개념을 노트와 단어장에 정리했습니다. 인터넷에 있는 단어장들도 유용하지만 너무 정의만 나와 있어서 이것만으로 점수를 잘 받기는 힘듭니다. 정의 외 사항을 알아야 합니다. 고득점이 목표가 아니라면 단어장 만으로 어느 정도 커버가 가능합니다.
수집 기술, 적제 기술 , 평가지표 , 모델, 데이터 전처리 기법, 통계량 등
계산 문제도 계속해서 1문제 정도 나왔었기 때문에 기본적인 계산을 외워두었다. 예. 오차 행렬에서 계산할 수 있는 다양한 지표, 장바구니 분석 , 신경망 출력 등
2.2 작업형
(a) 작업형 1
먼저 책에 있는 코드 다 해보고 저만의 베이스 라인 코드로 정리하고 연습은 캐글에서 연습하면서 마무리했습니다. 아직 시험 시행이 당시 2회 차 밖에 되지 않아 정보가 얼마 없어서 완벽하게 커버 가능한 교재는 없습니다.교재 하나만 공부하는 것보다 여러 소스를 활용해서 공부하면서 다양한 유형을 풀어보는 것을 추천드립니다. 작업형 1에서는 다양한 데이터 타입 전처리, 데이터 타입, 결측치, 이상치, 스케일링 , 정렬, 그룹화, 특정 기준으로 중복 제거, 인코딩하고 데이터 추출하는 연습을 했습니다. 3문제 5분 내에 다 풀 수 있을 정도로 했습니다.
R dplyr, 파이썬은 Numpy, Pandas, sklearn으로 데이터 조작을 할 줄 알아야 한다. 모른다면 기간이나 시간을 더 투자해야 합니다.
ADP, 빅데이터 분석기사 준비한 분이 정리한 사이트로 입문부터 100개 정도의 연습문제들이 있습니다.
위의 빅데이터 분석기사 실기 준비 놀이터보다는 약간 난이도 있습니다.
작업형 1 팁
작업형 1은 부분 점수 없으므로 각 절차마다 값들을 여러 번 확인하자. 예로 작업형 1에서 정수 값을 출력하라 했는데 10.0으로 제출했다면 float형이기 때문에 틀리게 됩니다.
print(변수) 변수에 하나의 값을 할당하여 출력하라고 지시 나왔었기 했지만 4회 가채점에서는 print(값) 넣어도 정답 처리해주었습니다. 임의 값 대입하여 출력 시 0점이 되기 때문에 이러함을 방지하는 것으로 문제에서도 변수로 출력하라고 명시되어 있습니다.
ans=4
print(ans)#지시사항에 나온 것
print(4) #이번에 정답처리 해줌
copy() 데이터 프레임 복사해두기
Pandas에서 제공하는 기본 통계 팁
분산, 표준편차 구하는 것은 넘파이 함수가 아닌 판다스 메소드 이용하셔야 합니다. 넘파이는 모 표준편차를 구하는데 np.std(ddof=1)로 하면 동일하긴 합니다.
import pandas as pd
df=pd.read_csv('data/X_train.csv')
df.col.min() #max, min, mean, median, mode , sum, count(결측값 제외)
df.quantile(.25) #제1분위수 #quantile,var, std skew, kurt
df.col.cumsum()[:1]#cumsum, cumprod ,cummax, cummin
df.col.sem() #sem , mad
df.col.abs()
df.col.corr()
a=pd.DataFrame({'test':[1,1,2,3,4]})
print(a.test.prod())
#>24
print("f1:", df['f1'].prod()) #열내 곱 (예.해당 열 내 값들 모두 곱함
print(help(pd.DataFrame.prod))
판다스 데이터 프레임 컬럼 많은 경우 … 생략되는 경우 전체 컬럼 볼 수 있도록 환경설정 바꾸기
pd.set_option(’display.max_columns’,None)
코딩은 계속 실행하면서 print()로 확인하면서 진행하자
평소 연습에도 하나의 블록에 실행해서 하자.
(b) 작업형 2
일정한 분석 파이프라인이 존재하여 자신만의 베이스라인 코드를 만들고 살을 붙여나가는 것을 추천드립니다. 볼드체로 된 부분은 필수 전처리입니다.
💡 베이스 라인 코드 1. X_train , y_train , X_test 데이터 로드 2. 데이터 전처리 (결측치 제거/대체, 중요도가 낮은 컬럼 제거 (예. index, id), 스케일링, 명목형 변수 제외하거나 인코딩 3. 학습 데이터에 학습 데이터 셋 홀드 아웃이나 교차 검증 4. 회귀/분류 모델 학습 5. 하이퍼 파라미터 튜닝 6.X_test 추론 분류 predict(클래스 값), predict_progba (확률) 회귀 predict(실수 값) 7. 제출 형식에 맞춰 데이터 데이터프레임을 csv형태로 제출 pd.to_csv(index=False) index=Fasle하지 않아도 4회 때에는 감점 없었음
작업형 2 팁 - 기본 코드 뼈대(대략적인 순서 보여주기 용) 빅데이터 분석기사 체험하기 작업형 ( Python 코드 )에 나온 코드 순서대로 하는 정도입니다. 이부분이 익숙하신 분들은 여기서 모델 지표 높이거나 다른 파트에 더 투자 하시면 됩니다.
#1. 주어진 데이터를 확인
pd.read_csv()
df.head()
#데이터 탐색
df.info() #결측치, 데이터타입, 행, 열 정보 보기 가능
df.describe()
#2. 데이터 전처리
#2.1 결측치 존재한다면 결측치 처리(결측치가 너무 많다면 변수 삭제, 적당하면 평균대체 등)
df.dropna()
df.fillna()
#연속형 변수들의 통계량 산출 > 변수들의 최대-최소 분포가 차이가 많이 난다면 스케일링 필요
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform()
sclaed_df = pd.DataFrame(scaled_data,columns=df.columns)
#이산형변수는 one-hot encoding이나 label encoding 등을 수행
pd.get_dummies()
encoder = LabelEncoder()
encoded_data = encoder.fit_transform()
#파생변수를 만들면 좋을지> 년/월/일/시/분/초 변수는 년, 월, 일, 시, 분, 초로 6개의 변수 분리하면 성능이 더 좋아질 수 있음, 형제자매수, 부모수 2개의 변수는 가족수=형제자매수+부모수로 변환하면 성능이 좋아질 수 있음
#3. 모델링 학습
model = XGBClassifier( )
model.fit(X_train, y_train)
prediction1 = model.predict_proba(X_test)
prediction2 = model.predict(X_test)
#5. 평가
print( roc_auc_score(y_val,prediction[:,:1]))
#6. 제출파일 생성
pd.DataFrame({'Id': y_test.Id, 'given_column': prediction2}).to_csv('수험번호.csv',index=False)
저는 모델은 각 유형별로 주로 사용할 모델 2~3개 정해놓고 voting형식으로 앙상블 했습니다. 합격선까지는 이 정도는 하지 않아도 random forest나 XGBoost와 같은 앙상블 모델 하나만 사용해서 성능을 높여주는 하이퍼파라미터를 찾으면 됩니다. (하지만 이 모델들이 항상 좋다는 의미는 아닙니다.) RandomForest, XGBoost와 같이 전반적으로 성능이 좋은 앙상블 모델 기준으로 연습하고 해당 머신러닝 모델의 중요한 하이퍼파라미터 암기해두어 하이퍼 파라미터 튜닝이 필요한 경우 합니다.
시간이 부족하거나 부담이 되시는 분들은 Random Forest(랜덤 포레스트)와 같은 의사결정 나무(Decision Tree) 계열의 앙상블 모델을 준비하면 따로 특성 스케일링할 필요도 없어서 부담감이 덜 해서 많이 추천된다.
싸이킷런 라이브러리
####### 라이브러리 모음
import pandas as pd
import numpy as np
# 데이터셋 불러오기
from sklearn.datasets import load_boston
# train, test 나누기
from sklearn.model_selection import train_test_split
# Scaling , encoding, transforming
from sklearn.preprocessing import (OneHotEncoder, LabelEncoder,
StandardScaler, MinMaxScaler, PowerTransformer, QuantileTransformer)
# 분류 모델부터 평가지표
from sklearn.ensemble import RandomForestClassifier(n_estimators, max_features.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.svm import svm
from sklearn.metrics import accuracy_score, roc_auc_score, f1_score,confusion_matrix
# 회귀
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import svm
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, #MSE 작을 수록
np.square(mean_squared_error)
# 경고 무시
import warnings
warnings.filterwarnings(action = 'ignore')
from datetime import datetime
from sklearn.model_selection import KFold, StratifiedKFold, train_test_split, GridSearchCV, cross_val_score
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
from sklearn.linear_model import LinearRegression, ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
경고 문장 안 나오게 하는 방법
import warnings
warnings.filterwarnings('ignore')
문제를 잘 읽고 예시 출력이랑 동일한지 요구한 사항을 잘 따렀는지 확인합니다.
예로 작업형 2에서 결과물을 확률 값으로 줘야 하는지 아니면 분류된 값으로 줘야 하는지 나와 있습니다.
칼럼명 잘 맞았는지, 특정 클래스의 확률을 잘 냈는지, 제시된 예시 양식에 잘 맞춰 냈는지 확인합니다.
random_state 시드 고정해서 랜덤성을 최대한 통제하기
3. 공부 전략
실기는 단답형 30점 10문제, 작업형 1 30점 3문제, 작업형 2 40점 1문제 중에서 유형 상관없이 60점 이상이면 합격합니다. 이 때문에 취득이 상대적으로 쉽습니다 시간이 많이 부족한 상태라면 자신이 강한 부분을 중심으로 준비하는 게 좋습니다. 이론 쪽이 강하다면 작업형과 정말 기본적으로 제출할 수 있는 정도로만 제출하면 되고 이론보다 작업형이 더 쉬워서 데이터 전처리랑 하이퍼 파라미터 튜닝까지 정도로 하면 됩니다. 실기 1,2 유형 최대한 만점 가까이 받도록 준비하고 실기 1,2 유형 10~ 20 점 감점 감안해서 필답형 최대 3 개(9점)~7개(21점) 필기나 실기 1에 선택해서 시간을 더 투자하면 됩니다. 실기 1,2 유형 최대한 만점 가까이 받도록 준비하고 실기 1,2 유형 10~ 20 점 감점 감안해서 필답형 최대 3 개(9점)~7개(21점) 필기나 실기 1에 선택해서 시간을 더 투자하면 됩니다. 2 유형은 2,3회는 이진 분류 모델, 4회 다중 분류가 나왔습니다. 2 유형은 평가 문제 때문에 명확한 지도 학습이 주로 나올 것으로 예상됩니다. 크롤링은 제공하는 라이브러리에 크롤링 가능한 beautifulsoup4, selenium 라이브러리 제공하는 것을 알 수 있지만 아직까지 4회 차에서도 에러가 나오는 시험환경에서는 한동안은 힘들 것으로 예상됩니다. 또, 시험 자체가 1분이라는 제 한 시간 안에 코드가 모두 실행돼야 하는 제한 때문에 어려운 문제 출제할 확률이 낮습니다 빅데이터 분석기사 합격률은 실기가 필기보다 높은 이유가 필기 합격자가 실기도 잘할 확률이 높아서도 있지만 아직까지는 난이도가 있지 않습니다. 작업형 2를 완전히 이해하지 않고 외워서 하시는 분들도 있었습니다. Python, R이 처음이라면 주로 사용하는 코드들만 외워도 되지만 첫 장벽이 매우 높게 느껴질 것입니다. 코드도 처음인데 이것으로 데이터 핸들링부터 머신러닝까지? 이런 경우에는 파이썬/R 기초 -> Pandas -> Scikitlearn 순서로 공부하시는 것을 추천드립니다. 언어를 할 줄 알고 해당 라이브러리로 머신러닝 경험이 있다면 유형만 익혀서 2주 내외로 바짝 공부하면 가능합니다. 사실 개인차가 있기 때문에 며칠 만에 했다 이런 후기에 너무 연연하지 않으셨으면 합니다. 그렇게 해서 취득해봤자 남는 게 없기 때문입니다.