빅데이터분석기사 실기 응시환경
데이터 분석기사 실기 시험은 단답형과 작업형 1,2 로 이루어 진다.
- 시험 시간: 10:00~13:00 (3시간)
- 언어: R, Python 중 선택
- Python 주요 라이브러리 Pandas(판다스), scikit-learn(사이킷런), Numpy(넘파이)
- R 주요 라이브러리
- dplyr
- 단답형
- 30점 (10Qs *3 점)
- 작업형
- 1유형 데이터 처리 30점(3Qs*10점)
0.빅데이터분석기사 실기 응시환경 특징
대부분이 주피터 노트북 환경에서 연습하다가 시험직전에 시험 응시 환경가 유사한 환경을 미리 체험하거나 연습한다. 그렇다면 실기 응시 환경은 어떻게 다를까?
한국 데이터 진흥원 홈페이지에 가면 시험 환경을 테스트할 수 있는 사이트를 서비스하고 있다.
응시 환경 미리 체험하기
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
1. 환경설정
톱니바퀴 모양을 누르면 화면 설정이 가능하다. 글의 줄 간격과 전체 화면의 비율 설정이 가능하다. 본인이 익숙한 환경 차이가 크지 않는 이상 따로 크게 만질 것 없다.
| 콘텐츠 영역 | 에디터 영역 |
| 단답형, 작업형 | 작업형 |
| 문제가 나오는 영역을 의미함 | 코드 작성 가능한 에디터 영역 |
|
|
탭 사이즈는 Tab키 한 번 누르면 indent가 기본적으로 몇 개의 스페이스를 갖고 들여 쓰기를 하는지를 정한다.
예. tab size=2이면 tab 한번 누르면 자동으로 스페이스 두 개 눌러 '들여쓰기'한 효과가 나온다.
이미지에 보면 탭은 아무 효과가 없지만 마우스 커서가 스페이스 2번과 같이 이동되어 있고 스페이스로 하는 경우 한 스페이스 당.으로 표시되며 들여 쓰기가 된다.

단답형(좌측)과 작업형(우측) 환경설정은 하단 이미지와 같다.
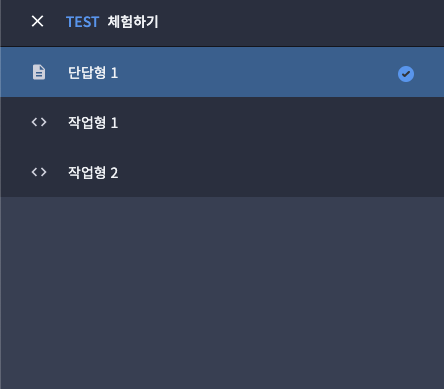
단답형 응시 환경 특징
- 콘텐츠는 복사, 붙여넣기 불가
- 숫자, 한글, 영문 , 스페이스, 특수문자 입력 가능
예시. 여러 명의 사용자들이 컴퓨터에 저장된 많은 자료들을 쉽고 빠르게 조회, 추가, 수정, 삭제할 수 있도록 해주는 소프트웨어는 무엇인가?
답안 :DBMS
제출을 하게 되면 제출 완료 표시와 함께 제출되었습니다. 채점 결과는 공개하지 않습니다. 라는 메시지가 나왔다가 사라진다.
좌측 햄버거 아이콘을 누르면 각 문제별로 제출되었는지 확인이 가능하고 색상으로 현재 어떤 페이지에서 문제를 풀고 있는지 알 수 있다.
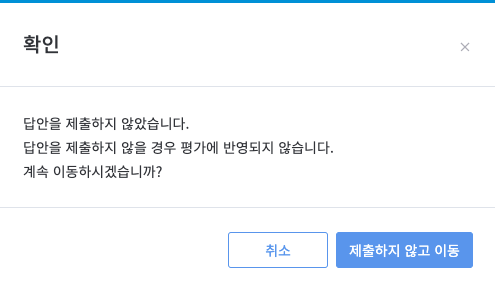
만약 제출하지않고 다음 문제로 넘어가면 경고 메시지가 나온다.
작업형 응시 환경 특징
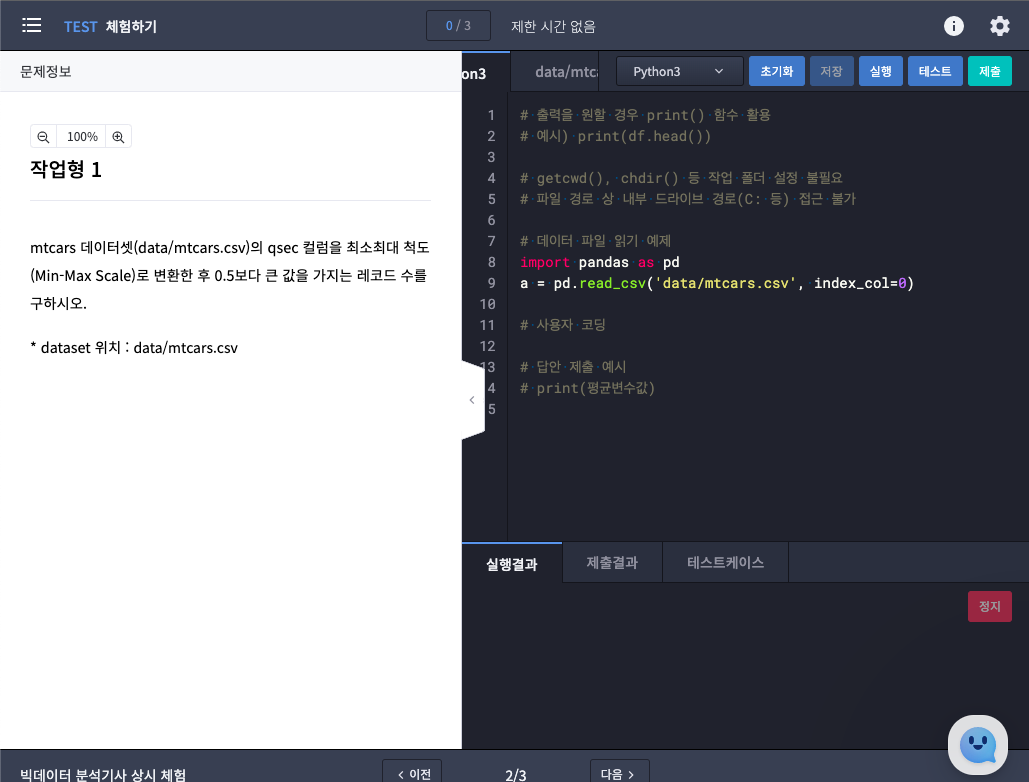
1. Groom IDE(통합 개발 환경) 기반
클라우드 환경이기 때문에 브라우저를 통해서 환경에 접속해야 한다.
시험 진행 시에는…
- 크롬 브라우저를 이용해서 https://dataq/goorm.io 에 접속한다
- 수험번호는 id, 감독관 안내에 따라 비밀번호 입력하 시험을 본다.
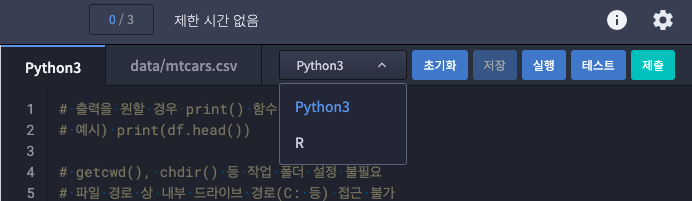
2. Python, R 언어 선택 가능
2.1 언어별 제공하는 라이브러리와 버전
선택하지 않은 언어에서 메모장처럼 사용 가능하다. 특히 하라 미터 파라미터 튜닝을 해서 값 비교해야한느데 주석 처리하기 귀찮은 경우라면 유용하다
(1) 시험 환경(Python)에 설치된 라이브러리
0 xgboost 1.4.2
1 threadpoolctl 2.2.0
2 soupsieve 2.2.1
3 setuptools 57.4.0
4 selenium 3.141.0
5 scipy 1.7.0
6 scikit-learn 0.24.2
7 pytz 2021.1
8 python-dateutil 2.8.2
9 pyparsing 2.4.7
10 pip 21.1.3
11 pillow 8.3.1
12 pandas 1.3.0
13 numpy 1.21.1
14 matplotlib 3.4.2
15 kiwisolver 1.3.1
16 joblib 1.0.1
17 distlib 0.3.2
18 cython 0.29.24
19 cycler 0.10.0
20 beautifulsoup4 4.9.3
21 wheel 0.30.0
22 urllib3 1.22
23 unattended-upgrades 0.1
24 ssh-import-id 5.7
25 six 1.11.0
26 secretstorage 2.3.1
27 requests 2.18.4
28 pyxdg 0.25
29 python-apt 1.6.5+ubuntu0.6
30 pygobject 3.26.1
31 pycrypto 2.6.1
32 keyrings.alt 3.0
33 keyring 10.6.0
34 idna 2.6
35 cryptography 2.1.4
36 chardet 3.0.4
37 certifi 2018.1.18
38 asn1crypto 0.24.0
(2) 시험 환경(R)에 설치된 라이브러리
#print(as.data.frame(installed.packages()[,c(3:4)]))
askpass 1.1 <NA>
base64enc 0.1-3 <NA>
BH 1.75.0-0 <NA>
brio 1.1.2 <NA>
callr 3.7.0 <NA>
caret 6.0-86 <NA>
CARRoT 2.5.1 <NA>
Ckmeans.1d.dp 4.3.3 <NA>
cli 2.5.0 <NA>
clipr 0.7.1 <NA>
colorspace 2.0-0 <NA>
commonmark 1.7 <NA>
cpp11 0.2.7 <NA>
crayon 1.4.1 <NA>
cyclocomp 1.1.0 <NA>
data.table 1.14.0 <NA>
desc 1.3.0 <NA>
DiagrammeR 1.0.6.1 <NA>
diffobj 0.3.4 <NA>
digest 0.6.27 <NA>
doParallel 1.0.16 <NA>
downloader 0.4 <NA>
dplyr 1.0.5 <NA>
e1071 1.7-6 <NA>
ellipsis 0.3.1 <NA>
evaluate 0.14 <NA>
fansi 0.4.2 <NA>
farver 2.1.0 <NA>
float 0.2-4 <NA>
foreach 1.5.1 <NA>
generics 0.1.0 <NA>
ggplot2 3.3.3 <NA>
glue 1.4.2 <NA>
gower 0.2.2 <NA>
gridExtra 2.3 <NA>
gtable 0.3.0 <NA>
highr 0.9 <NA>
hms 1.0.0 <NA>
htmltools 0.5.1.1 <NA>
htmlwidgets 1.5.3 <NA>
httpuv 1.6.0 <NA>
hunspell 3.0.1 <NA>
igraph 1.2.6 <NA>
influenceR 0.1.0 <NA>
ipred 0.9-11 <NA>
isoband 0.2.4 <NA>
iterators 1.0.13 <NA>
jpeg 0.1-8.1 <NA>
jsonlite 1.7.2 <NA>
knitr 1.33 <NA>
labeling 0.4.2 <NA>
later 1.2.0 <NA>
lava 1.6.9 <NA>
lazyeval 0.2.2 <NA>
lifecycle 1.0.0 <NA>
lmtest 0.9-38 <NA>
lubridate 1.7.10 <NA>
magrittr 2.0.1 <NA>
markdown 1.1 <NA>
mime 0.10 <NA>
mockery 0.4.2 <NA>
ModelMetrics 1.2.2.2 <NA>
munsell 0.5.0 <NA>
numDeriv 2016.8-1.1 <NA>
pillar 1.6.0 <NA>
pkgconfig 2.0.3 <NA>
pkgload 1.2.1 <NA>
plyr 1.8.6 <NA>
png 0.1-7 <NA>
praise 1.0.0 <NA>
pROC 1.17.0.1 <NA>
processx 3.5.1 <NA>
prodlim 2019.11.13 <NA>
promises 1.2.0.1 <NA>
proxy 0.4-25 <NA>
ps 1.6.0 <NA>
purrr 0.3.4 <NA>
R6 2.5.0 <NA>
randomForest 4.6-14 <NA>
rbibutils 2.1.1 <NA>
RColorBrewer 1.1-2 <NA>
Rcpp 1.0.6 <NA>
Rdpack 2.1.1 <NA>
readr 1.4.0 <NA>
recipes 0.1.16 <NA>
rematch2 2.1.2 <NA>
remotes 2.3.0 <NA>
reshape 0.8.8 <NA>
reshape2 1.4.4 <NA>
rex 1.2.0 <NA>
rlang 0.4.10 <NA>
rmarkdown 2.7 <NA>
rprojroot 2.0.2 <NA>
rstudioapi 0.13 <NA>
scales 1.1.1 <NA>
SQUAREM 2021.1 <NA>
stringi 1.5.3 <NA>
stringr 1.4.0 <NA>
sys 3.4 <NA>
testthat 3.0.2 <NA>
tibble 3.1.1 <NA>
tidyr 1.1.3 <NA>
tidyselect 1.1.0 <NA>
timeDate 3043.102 <NA>
tinytex 0.31 <NA>
titanic 0.1.0 <NA>
utf8 1.2.1 <NA>
vcd 1.4-8 <NA>
vctrs 0.3.7 <NA>
viridis 0.6.0 <NA>
viridisLite 0.4.0 <NA>
visNetwork 2.0.9 <NA>
waldo 0.2.5 <NA>
withr 2.4.2 <NA>
xfun 0.22 <NA>
xgboost 1.4.1.1 <NA>
xmlparsedata 1.0.5 <NA>
yaml 2.2.1 <NA>
zoo 1.8-9 <NA>
base 3.6.3 base
boot 1.3-25 recommended
class 7.3-17 recommended
cluster 2.1.0 recommended
codetools 0.2-18 recommended
compiler 3.6.3 base
datasets 3.6.3 base
foreign 0.8-76 recommended
graphics 3.6.3 base
grDevices 3.6.3 base
grid 3.6.3 base
KernSmooth 2.23-18 recommended
lattice 0.20-41 recommended
MASS 7.3-53 recommended
Matrix 1.3-2 recommended
methods 3.6.3 base
mgcv 1.8-33 recommended
nlme 3.1-151 recommended
nnet 7.3-14 recommended
parallel 3.6.3 base
rpart 4.1-15 recommended
spatial 7.3-11 recommended
splines 3.6.3 base
stats 3.6.3 base
stats4 3.6.3 base
survival 3.2-7 recommended
tcltk 3.6.3 base
tools 3.6.3 base
utils 3.6.3 base
3. 코드 런타임 1분 제한
실행 시간제한이 1분이므로 특히 작업형 3에서 모든 과정이 1분 내에 끝나야 함을 주의하자.
실행 버튼을 누르면 하단에 실행결과에서 ‘프로세스가 시작되었습니다.’와 함께 현재 실행시간/제한시간 1분이 나오고 현재 실행을 정지하기 위한 버튼이 생긴다.

4. 파일 경로
따로 파일 경로 설정할 필요 없음, 항상 data/ 내에 있음
5. 제약 사항
- 라인별 실행 불가
- 그래프 시각화 불가
- 단축키 미제공
- 패키지 추가 설치 불가함으로 패키지 확인
- 콘텐츠는 복사, 붙여 넣기 불가하며 코드는 복사, 붙여넣기 사용 가능
- 노트북 형식이 아니기 때문에
print()함수를 사용해야지만 출력 - 실제 시험 환경에서는 1000줄만 출력
- 자동 완성 기능 미제공
특히 제약사항 중 자동완성 기능을 제공하지 않기 때문에 대략적으로 어떤 함수가 어느 라이브러리에 있는지 알면 된다.
- R은 help(), ? 함수와 파이썬은 help(), dir() 함수를 적극 이용해야 한다.제가 Python기준으로 준비하여 Python위주로 설명 드립니다.
help()- 키워드, 함수, 클래스, 메서드에 대해서 파라미터, 리턴 값 , 예시 사용법을 알려주는 내장 함수
dir()- 객체가 갖고 있는 변수와 메서드 보여주는 내장 함수
- sklearn은
dir()대신에__all__을 이용해야 하위 모듈 확인 가능하다.- sklearn 하위 모듈 내에서는
dir(), __all__둘 다 동일하나dir()는 알파벳순 정렬해준다.
- sklearn 하위 모듈 내에서는
- R은 installed.packages(), ?caret::traiin() 이런 식으로 사용 할 줄 알아야한다.
예를 들어 싸이킷런에서 앙상블 모듈을 사용하고 싶은데 기억이 나지 않는다. 그렇다면 print(sklearn.__all__)을 통해 하위 모듈을 확인할 수 있다. ensemble이 하위 모듈에 있는 것을 알 수 있다.
import sklearn
print(dir(sklearn))
# ['__SKLEARN_SETUP__', '__all__', '__builtins__', '__cached__', '__check_build', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_config', '_distributor_init',
# 'base', 'clone', 'config_context', 'exceptions', 'get_config', 'logger', 'logging', 'os', 'random', 'set_config', 'setup_module', 'show_versions', 'sys', 'utils']
print('\n',sklearn.__all__) #하위 모듈 출력
#['calibration', 'cluster', 'covariance', 'cross_decomposition', 'datasets', 'decomposition', 'dummy',
#'ensemble', 'exceptions', 'experimental', 'externals', 'feature_extraction', 'feature_selection', 'gaussian_process', 'inspection', 'isotonic', 'kernel_approximation',
#'kernel_ridge', 'linear_model', 'manifold', 'metrics', 'mixture', 'model_selection', 'multiclass', 'multioutput', 'naive_bayes', 'neighbors',
#'neural_network', 'pipeline', 'preprocessing', 'random_projection', 'semi_supervised', 'svm', 'tree', 'discriminant_analysis', 'impute', 'compose',
#'clone', 'get_config', 'set_config', 'config_context', 'show_versions']실제 시험 환경에서import 하는 경우 특정 라이브러리도 임포트 해야 help(), dir() 에러 발생하지 않는다.
ensemble모델을 불러오고 나서 해당 하위 모듈 조회가 가능하다. 앙상블 모델 중에서 랜덤 포레스트 분류기를 까먹었다면 내부에서 RandomForestClassifier를 확인이 가능하다.
print('\\n',sklearn.ensemble.__all__)
#AttributeError: module 'sklearn' has no attribute 'ensemble'
import sklearn.ensemble
print('\\n',dir(sklearn.ensemble))
#['AdaBoostClassifier', 'AdaBoostRegressor', 'BaggingClassifier', 'BaggingRegressor', 'BaseEnsemble', 'ExtraTreesClassifier', 'ExtraTreesRegressor', 'GradientBoostingClassifier', 'GradientBoostingRegressor', 'IsolationForest', 'RandomForestClassifier', 'RandomForestRegressor', 'RandomTreesEmbedding', 'StackingClassifier', 'StackingRegressor', 'VotingClassifier', 'VotingRegressor', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_bagging', '_base', '_forest', '_gb', '_gb_losses', '_gradient_boosting', '_iforest', '_stacking', '_voting', '_weight_boosting', 'typing']
print('\\n',sklearn.ensemble.__all__)
#['BaseEnsemble', 'RandomForestClassifier', 'RandomForestRegressor', 'RandomTreesEmbedding', 'ExtraTreesClassifier', 'ExtraTreesRegressor', 'BaggingClassifier', 'BaggingRegressor', 'IsolationForest', 'GradientBoostingClassifier', 'GradientBoostingRegressor', 'AdaBoostClassifier', 'AdaBoostRegressor', 'VotingClassifier', 'VotingRegressor', 'StackingClassifier', 'StackingRegressor']
포스팅이 도움이 되셨다면 좋아요와 댓글 부탁드립니다 :)
빅데이터 분석기사에 대한 모든 것!
아직 이 빅데이터 기사 시험은 시험 시행을 2회밖에 하지 못하여 다른 기사 시험에 대해 정보가 부족해서 관련 포스팅을 적었습니다. 아직 정보가 많이 없어서 기사시험도 준비할 생각도 없었는
potato-potahto.tistory.com
빅데이터 분석기사 체험하기 작업형 ( Python 코드 )
빅데이터 분석기사 체험하기 작업형 ( Python 코드 )
빅데이터 분석기사 체험환경 작업형 예시문제 체험 환경에서 제공했던 각 유형별 예시 문제와 작업형 1,2에서 사용한 데이터셋 2개를 제공하고 있어 다운로드해서 연습하실 수 있습니다. 시험
potato-potahto.tistory.com
빅데이터분석기사 실기 만점자 합격 후기(고득점 공부방법, 꿀팁,독학)
빅데이터분석기사 실기 만점자 합격 후기(고득점 공부방법, 꿀팁,독학)
다행히 빅데이터 분석 기사 합격후기로 돌아왔습니다. 저는 실기 만점 받고 합격하였습니다. 제4회 빅데이터 분석기사 실기가 시험일로부터 2주 뒤 오후 3시에 가채점 결과 발표되었습니다. 가
potato-potahto.tistory.com
제 4회 빅데이터분석기사 실기 후기, 가답안
제4회 빅데이터 분석기사 실기 후기 2022년의 첫 빅데이터 분석기사 실기로 시험 치고 나서 카페 가답안과 제 답안 확인하고 정리해서 올립니다! 그리고 문제 복원은 한국 데이터 진흥원의 빅
potato-potahto.tistory.com
[서평] 데이터캠퍼스 빅데이터 분석기사 실기 교재 후기
[서평] 데이터캠퍼스 빅데이터 분석기사 실기 교재 후기
데이터캠퍼스 빅데이터 분석기사 실기 해당 날짜 기준 (2021년 9월)으로 빅데이터 분석기사 실기 교재가 나온 것이 없어서 미리 공부하고 싶어 찾던 도중 유일하게도 데이터 캠퍼스에서 Python기반
potato-potahto.tistory.com
[서평] 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 후기
[서평] 2022 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 후기
현재 실기 교재는 6군데에서 나오고 있고 필기, 실기 수험서 중 뚜렷하게 이거다! 할 수험서가 나타나지 않은 것으로 알고 있습니다. 그리고 실기 교재 출판한 출판사도 많지 않고 대부분 Python으
potato-potahto.tistory.com
'Challenges > 빅데이터분석기사' 카테고리의 다른 글
| 제 4회 빅데이터분석기사 실기 후기, 가답안 (2) | 2022.06.26 |
|---|---|
| 빅데이터 분석기사 체험하기 작업형 ( Python 코드 ) (0) | 2022.06.20 |
| [리뷰] 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 (0) | 2022.05.22 |
| 빅데이터 분석기사 필기 합격 후기 (0) | 2021.10.22 |
| [리뷰] 데이터캠퍼스 빅데이터 분석기사 실기 교재 후기 (0) | 2021.10.12 |