빅데이터 분석기사 체험환경 작업형 예시문제
체험 환경에서 제공했던 각 유형별 예시 문제와 작업형 1,2에서 사용한 데이터셋 2개를 제공하고 있어 다운로드해서 연습하실 수 있습니다.
시험 체험환경 관련 궁금하시다면 이전 포스트 확인해주세요
빅데이터분석기사 실기 시험 응시환경 팁
빅데이터분석기사 실기 응시환경 데이터 분석기사 실기 시험은 단답형과 작업형 1,2 로 이루어 진다. 시험 시간: 10:00~13:00 (3시간) 언어: R, Python 중 선택 Python 주요 라이브러리 Pandas(판다스), scikit-
potato-potahto.tistory.com
단답형
여러 명의 사용자들이 컴퓨터에 저장된 많은 자료들을 쉽고 빠르게 조회, 추가, 수정, 삭제할 수
있도록 해주는 소프트웨어는 무엇인가?
DBMS
작업형1
- 작업형은 주로 데이터 핸들링에 관한 문제다.
Q. mtcars 데이터셋(mtcars.csv)의 qsec 칼럼을 최소 최대 척도(Min-Max Scale)로 변환한 후 0.5보다
큰 값을 가지는 레코드 수를 구하시오.
- dataset위치: data/mtcars.csv
작업형 1 문제풀이
예시에서는 최소-최대 스케일링 하여 특정 값들의 개수를 구하라고 한다. 최소-최대 정규화를 구하는 방법은 사용하는 라이브러리나 모듈에 따라 4개 정도 나온다.
1. 라이브러리 호출하고 데이터 로드하여 준비하기
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
data=pd.read_csv('data/mtcars.csv')2. 최소-최대 정규화 적용하기
스케일링 적용하는 방법은 이미 구현되어 있는 함수나 객체를 가져다 쓰거나 직접 계산해야 한다. 라이브러리로는 싸이킷런을 추천하며 다른 라벨 인코딩, 머신러닝 알고리즘을 자주 사용하는 데 사용 방식이 비슷하기 때문에 익히기 쉽다.
Min-Max Normalization(최소-최대 정규화) = \( \frac{x-Min}{Max-Min} \)
2.1 Scikit-learn(싸이킷럿)라이브러리 MinMaxScaler() 이용
data[['qsec']]=MinMaxScaler().fit_transform(data[['qsec']])
print(data.qsec.head())fit(), transofrm()의두 단계를fit_transform()함수로 스케일링 값 계산하여 이를 바탕으로 계산하는 것을 하나로 해결
2.2 Scikit-learn(싸이킷럿) 라이브러리 minmax_scale() 이용
from sklearn.preprocessing import minmax_scale
data['qsec'] = minmax_scale(data['qsec'])
print(data.qsec.head())
2.3 직접 계산하기
- 판다스를 이용해서 바로 적용 가능하다. 이 외에도 넘파이로도 계산 가능하다.
- 함수로 만들어서 풀 수도 있고 변수에 할당해서 풀 수도 있다. 재사용할 필요가 없어서 바로 적용하였다
(1) Pandas
Min= data.qsec.min()
Max= data.qsec.max()
data[['Pandas']]= (data[['qsec']] - Min)/ (Max-Min)
print(data.Pandas.head())(2) Numpy
import numpy as np
Min= np.min(data.qsec)
Max= np.max(data.qsec)
data[['Numpy']]= (data[['qsec']] - Min)/ (Max-Min)
print(data.Numpy.head())

3. 조건부 추출하기
qsec에 0.5 값보다 큰 값들만 추출한다.
print(len(data[data.qsec>0.5]))
푸는 방식은 1번이나 3번의 Pandas로 직접하는 방법을 추천한다. 작업형 1에서 pandas라이브러리로 데이터 전처리, 변환해야 하는 경우가 많다. 또 작업형 2에서 싸이킷런을 사용하다 보면 객체 불러오는 1번 방식으로 많이 사용하기 때문에 추천한다.
작업형2
- 학습 데이터셋에서는 피쳐와 라벨 데이터와 테스트 데이터는 피쳐 데이터를 기반으로 라벨 데이터를 얼마나 잘 맞추는지를 채점하기 때문에 테스트 데이터셋의 라벨을 제공하지 않는다. 데이터를 제외하고 모두 제공한다.
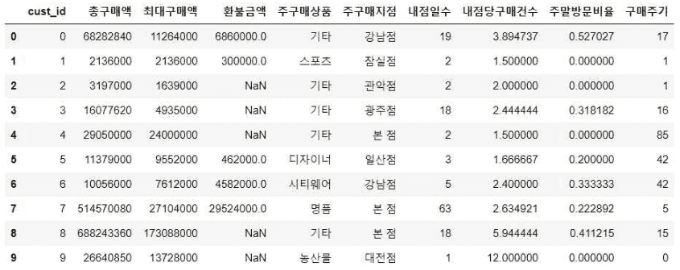
아래는 백화점 고객의 1년 간 구매 데이터이다. 아 래 (가) 제공 데이터 목록
- y_train.csv : 고객의 성별 데이터 (학습용), CSV 형식의 파일
- X_train.csv, X_test.csv : 고객의 상품 구매 속성 (학습용 및 평가용), CSV 형식의 파일
- (나) 데이터 형식 및 내용
- ① y_train.csv (3,500명 데이터)

- custid: 고객 ID
- gender: 고객의 성별 (0: 여자, 1: 남자)
- ② X_train.csv (3,500명 데이터), X_test.csv (2,482명 데이터)
고객 3,500명에 대한 학습용 데이터(y_train.csv, X_train.csv)를 이용하여 성별 예측 모형을 만든
후, 이를 평가용 데이터(X_test.csv)에 적용하여 얻은 2,482명 고객의 성별 예측값(남자일 확률)을
다음과 같은 형식의 CSV 파일로 생성하시오.(제출한 모델의 성능은 ROC-AUC 평가지표에 따라
채점) <제출형식>
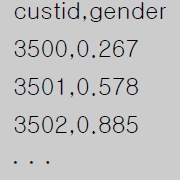
<유의사항>
- 성능이 우수한 예측모형을 구축하기 위해서는 적절한 데이터 전처리, 피처엔지니어링, 분류알고리즘, 하이퍼파라미터 튜닝, 모형 앙상블 등이 수반되어야 한다.
- 수험번호.csv파일이 만들어지도록 코드를 제출한다.
- 제출한 모델의 성능은 ROC-AUC형태로 읽어드린다.
작업형 2 문제풀이
베이스 라인 코드
- 데이터 읽기
- 탐색적 데이터 분석 info(), describe() , value_counts() 등을 이용하여 데이터 이해 높이기
- 필수 데이터 전처리: 결측치 처리, 인코딩
- 모델링(학습 및 평가
- csv 제출
가장 간단한 형태의 베이스라인 코드이다. 트리계열의 모델을 사용하면 스케일링을 하지 않아도 된다.
데이터 전처리시 파생 변수 생성하거나 스케일링을 통해서 수치형 데이터 범위 , 분포 조정이 가능하다.
범주형 데이터는 라벨 인코딩 말고 원핫인코딩도 있다.
여러 모델 비교하고 선택된 모델 하이퍼 파라미터 튜닝, 앙상블을 통해서 더 높은 지표 달성 가능하다.
# 출력을 원하실 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
# 데이터 파일 읽기 예
import pandas as pd
test = pd.read_csv("data/X_test.csv")
X = pd.read_csv("data/X_train.csv")
y = pd.read_csv("data/y_train.csv")
# 필수 전처리: 결측치 대체
X['환불금액']=X['환불금액'].fillna(0)
test['환불금액']=test['환불금액'].fillna(0)
# 전처리: 불필요한 컬럼 제외
X=X.drop(['cust_id'],axis=1)
cust_id=test.pop('cust_id')
# 필수 전처리: 범주형 데이터 수치화
import sklearn.preprocessing
dir(sklearn.preprocessing)
from sklearn.preprocessing import LabelEncoder
cols=['주구매상품','주구매지점']
for col in cols:
le=LabelEncoder()
X[col]=le.fit_transform(X[col])
test[col]=le.transform(test[col])
X.head()
# 모델링-모델 성능 확인
from sklearn.model_selection import train_test_split
X_tr,X_val,y_tr,y_val = train_test_split(X,y['gender'],test_size=0.2,random_state=2022)
import sklearn.ensemble
dir(sklearn.ensemble)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score
rf=RandomForestClassifier()
rf.fit(X_tr,y_tr)
print('acc',rf.score(X_val,y_val))
pred1=rf.predict_proba(X_val)
print('roc_auc:',roc_auc_score(y_val,pred1[:,1]) )
# 최종 모델
rf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=2022)
rf.fit(X, y['gender'])
pred_fin=rf.predict_proba(test)
#답안 제출
pd.DataFrame({'cust_id':cust_id,'gender':pred_fin[:,1]}).to_csv('123.csv',index=False)
print(pd.read_csv('123.csv'))
# 답안 제출 참고
# 아래 코드 예측변수와 수험번호를 개인별로 변경하여 활용
# pd.DataFrame({'cust_id': X_test.cust_id, 'gender': pred}).to_csv('003000000.csv', index=False)
가장 중요한 것은 제출한 답안이 요구하는 답안과 동일한지 확인!
요구사항을 잘 지키지 못해 감점되기도 하니 중요!
예시로 저장 시 index=False를 하지 않으면 우측 이미지와 같이 인덱스가 칼럼으로 생성되며 저장된다.
pd.DataFrame({'custid':cust_id,'gender':pred[:,1]}).to_csv('123.csv',index=False)
a=pd.read_csv('123.csv')
print(a)
pd.DataFrame({'custid':cust_id, 'gender':pred[:,1]}).to_csv('3.csv')
b=pd.read_csv('3.csv') #Unnamed: 0 생성됨
print(b)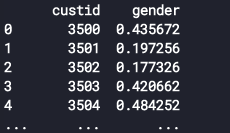

포스팅이 도움이 되셨다면 좋아요와 댓글 부탁드립니다 :)
빅데이터 분석기사에 대한 모든 것!
아직 이 빅데이터 기사 시험은 시험 시행을 2회밖에 하지 못하여 다른 기사 시험에 대해 정보가 부족해서 관련 포스팅을 적었습니다. 아직 정보가 많이 없어서 기사시험도 준비할 생각도 없었는
potato-potahto.tistory.com
빅데이터 분석기사 체험하기 작업형 ( Python 코드 )
빅데이터 분석기사 체험하기 작업형 ( Python 코드 )
빅데이터 분석기사 체험환경 작업형 예시문제 체험 환경에서 제공했던 각 유형별 예시 문제와 작업형 1,2에서 사용한 데이터셋 2개를 제공하고 있어 다운로드해서 연습하실 수 있습니다. 시험
potato-potahto.tistory.com
빅데이터분석기사 실기 만점자 합격 후기(고득점 공부방법, 꿀팁,독학)
빅데이터분석기사 실기 만점자 합격 후기(고득점 공부방법, 꿀팁,독학)
다행히 빅데이터 분석 기사 합격후기로 돌아왔습니다. 저는 실기 만점 받고 합격하였습니다. 제4회 빅데이터 분석기사 실기가 시험일로부터 2주 뒤 오후 3시에 가채점 결과 발표되었습니다. 가
potato-potahto.tistory.com
빅데이터분석기사 실기 시험 응시환경 팁
빅데이터분석기사 실기 응시환경 데이터 분석기사 실기 시험은 단답형과 작업형 1,2 로 이루어 진다. 시험 시간: 10:00~13:00 (3시간) 언어: R, Python 중 선택 Python 주요 라이브러리 Pandas(판다스), scikit-
potato-potahto.tistory.com
제 4회 빅데이터분석기사 실기 후기, 가답안
제4회 빅데이터 분석기사 실기 후기 2022년의 첫 빅데이터 분석기사 실기로 시험 치고 나서 카페 가답안과 제 답안 확인하고 정리해서 올립니다! 그리고 문제 복원은 한국 데이터 진흥원의 빅
potato-potahto.tistory.com
[서평] 데이터캠퍼스 빅데이터 분석기사 실기 교재 후기
[서평] 데이터캠퍼스 빅데이터 분석기사 실기 교재 후기
데이터캠퍼스 빅데이터 분석기사 실기 해당 날짜 기준 (2021년 9월)으로 빅데이터 분석기사 실기 교재가 나온 것이 없어서 미리 공부하고 싶어 찾던 도중 유일하게도 데이터 캠퍼스에서 Python기반
potato-potahto.tistory.com
[서평] 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 후기
[서평] 2022 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 후기
현재 실기 교재는 6군데에서 나오고 있고 필기, 실기 수험서 중 뚜렷하게 이거다! 할 수험서가 나타나지 않은 것으로 알고 있습니다. 그리고 실기 교재 출판한 출판사도 많지 않고 대부분 Python으
potato-potahto.tistory.com
'Challenges > 빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 실기 만점자 합격 후기(고득점 공부방법, 꿀팁,독학) (3) | 2022.08.10 |
|---|---|
| 제 4회 빅데이터분석기사 실기 후기, 가답안 (2) | 2022.06.26 |
| 빅데이터분석기사 실기 시험 응시환경 팁 (3) | 2022.06.06 |
| [리뷰] 이기적 빅데이터분석기사 실기 (필답형,R,Python 포함) 교재 (0) | 2022.05.22 |
| 빅데이터 분석기사 필기 합격 후기 (0) | 2021.10.22 |