- Pipeline으로 효율적 워크플로 : 여러개의 변환기와 분류기를 모델 연결
- 모델 성능 평가 : K겹 교차 검증, Holdout
- 학습곡선과 검증 곡선: 과대적합/과소적합 분석
- ML 세부 튜닝 : 그리드 서치
- 성능 평가 지표 :
- 이진 분류: 정확도, 재현율, 정밀도, F-1 점수, ROC, ROC AUC
- 다중 분류: 마이크로,마크로 평균 정밀도
- 불균형한 클래스
6.1 Pipeline으로 효율적인 워크플로
- Pipeline: meta-estimator, 여러개의 개별 변환기와 추정기를 감싼 Wrapper (연결)
- fit method호출시 데이터가 중간단계에 있는 모든 변환기의fit, transform차례로 거쳐 추정기 객체에 도달,학습
- predict
- 변환기: 입력에 대해fit, transform method지원으로 n단계
- StandardScaler :
- PCA
- 추정기: fit, predict method 구현,데이터 학습, 마지막 단계
- logistic Regression
예. 훈련세트 -> 특성 표준화 +PCA + Logistric Regression (학습 ,예측)

6.2 모델 성능 평가 테크닉(model validation technique): Resampling
검증: 성능 추정 방법으로 반복적으로 다른 파라미터 값에서 모델을 훈련한 후 예측 모델이 훈련에서 사용되지 않은 실제(unknown data)에서 얼마나 성능을 하는지 성능 일반화 평가
모델선택: 예측 성능 향상을 위해 하이퍼파라미터 튜닝 최적의 값 선택, 모델 비교
Re-sampling : 반복해서 트레이닝 셋에서 샘플들을 추출해서 모델에 재적합시켜서 모델에대한 추가적 정보를 얻음
- 각기 다른 샘플에 적합시킨 모델들마다 얼마나 다른지 비교 가능
- test error :새로운 관측값에 예측하는 통계적 학습 방법을 이용해서 평균전 에러 계산 ( holding out training data)
- training error :학습 방법에서 사용했었던 데이터에 예측하는 통계적 학습 방법을 이용해서 평균적 에러
validation set approach :랜던하게 학습에 사용하는 training set과 평가에 사용하는 validation set 을 특정 비율로 파티션 함.
- test error rate 가 상당히 변동성 높음( 샘플에 의존함)
- ONLY 관측값들의 일부분만 학습에 사용됨
- 검증셋의 에러는 테스트 에러보다 고평가
1) 교차검증(cross-validation, CV)
예측의 적합성의 평균 측정값을 합하여 더 정확한 모델 예측 성능의 추정값 갖음
- 과적합(overfitting), 편향 선택(selection bias) 문제 피함
- 예. LOOCV, holdout CV, k-fold CV
(1) Exhaustive cross-validation: 샘플을 training 과 검증 set으로 나누는 모든 가능한 방법
- Leave-p-out cross-validation, LpOCV: nCp(이항계수) 반복해서 p 개의 관측값을 검증셋으로 이용하고 나머지를 훈련에 사용
- :( 큰 n, 작은 p인경우 계산 비용 큼
- Leave-one-out cross-validation,LOOCV : LpOCV에서 p=1인 경우로nC1 (n번) 반복함
- 하나의 훈련 샘플이 n번 반복에서 테스트로 사용하고 거의 모든 관측치를 사용하여 훈련
- 편향(bias)과 분산이 작음
- 계산 비용 큼 : n번 n-1개의 데이터를 학습에 사용하므로 작은 경우 권장
- k-fold CV에서 k=n일때의 특별 케이스와도 같음
- k<n인경우 k-fold cv분산보다도 큼 (거의 비슷한 데이터로 학습을 하기때문에 양의 상관관계가 높음)


(2) Non-Exhaustive cross-validation : LpOCV의 근사로 모든 가능한 경우의수를 사용하지 않음
- 홀드아웃(holdout CV): 별도의 훈련, 테스트 세트 나누어 최적의 하이퍼 파라미터 나올때까지 반복
- 훈련 : 여러 모델 학습
- 검증: 평가 통해서 모델 선택
- 테스트: 최종 성능 평가(일반화 성능 추정 )
- 덜 편향 됨
- ///샘플 민감
- :( 나누는 방식에 따라서 성능 추정이 민감

- k겹 (k-fold CV) : 중복 허락하지 않고 훈련 데이터셋을 k개의 동일한 사이즈의 폴드로 랜덤하게 나누 훈련, 평가를 k번 반복
- 훈련: k-1 fold
- 평가 : 1 fold
- 서로 다른 독립적인 fold 에서 얻은 성능 추정을 기반으로 모델 편균 성능 계산

-
- 세트 분할에 덜 민감한 성능 추정
- 최적의 파이퍼 파라미터값 찾은후 전체 훈련세트 사용 모델 훈련 - 독립적인 테스트 세트 사용 최정성능 추정하여 더 많은 샘플로 학습하여 학습 알고리즘이 더 정확하고 안정적인 모델을 만들수 있기 때문
- 낮은 분산
- 훈련세트 크기가 작은 경우 k갯수 늘리어 더 많은 훈련데이터 사용 , 낮은 편향
- :( 알고리즘 실행 시간 증가, 분산이 높은 추정 만듦(훈련 폴드가 서로 비슷해짐)
- 훈련세트 크기가 큰경우 작은 k :) 계산 비용

- 계층적 k-겹 교차검증(stratified k-fold cross-validation)
- 각 폴드에서 클래스 비율이 전체 훈련 세트에 있는 클래스 비율을 대표하도록 유지
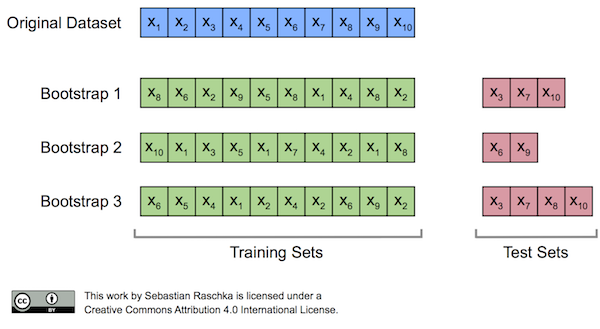
2) Bootstrapping
k번의 중복을 허용한 n 개 랜덤 재샘플링을 통해 모수(population)의 분포 추정하는 재표본(resampling) 방법
- 샘플 크기
- 반복
6.3 정확도 : 학습 곡선, 검증곡선을 사용한 알고리즈디버깅
목표 : 편향 분산 트레이드오프 bias-variance tradeoff
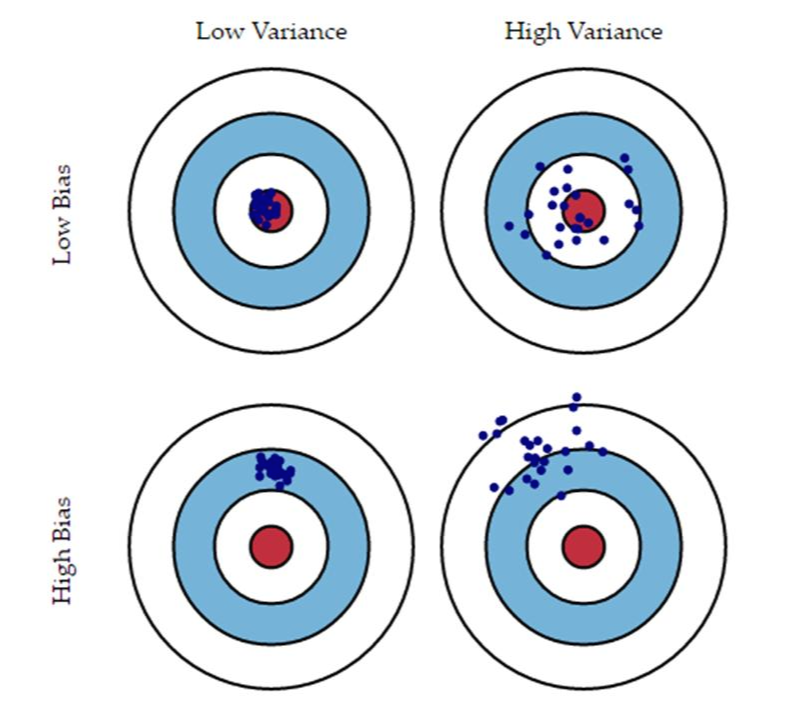
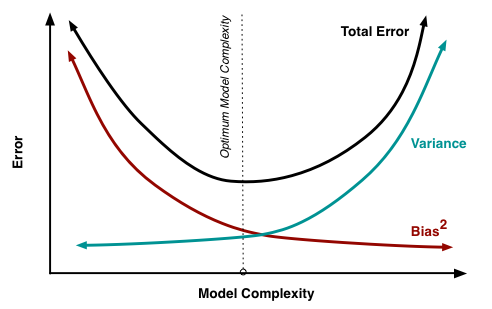
- 학습곡선: 훈련 정확도- 검증 정확도를 훈련 세트의 크기 함수로 그래프화하여 분산-편향 문제 분석
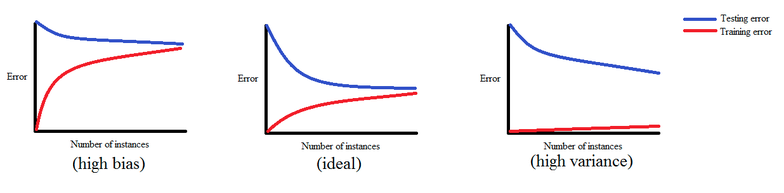
-
- 과대적합:높은 분산
- 모델이 데이터셋에 비해 복잡 : 자유도, 모델파라미터 많음
- 해결 :
- 더 많은 샘플 사용
- noise많은 경우 :(
- $$$
- 모델이 이미 최적화 된 경우
- 모델 복잡도 낮추기
- 규제 증가
- 특성 선택, 특성 추출통해 특성 개수 줄이기
- 더 많은 샘플 사용
- 훈련 정확도 - 검증 정확도를 훈련 세트의 크기 함수로 그래프 (분산-편향)
- 과소적합:높은 편향
- 해결:
- 모델 파라미터 늘리기( 추가적 특성 수집)
- svm, logistic regression classifier 규제 강도 줄이기
- 해결:
- 과대적합:높은 분산
- 검증 곡선: 과대적합,과소적합 문제 새결하여 모델 성능을 높일때 사용
- 모델 파라미터값의 함수- 정확도
- 과소적합: 규제강도 높은 경우
- 과대적합: 규제 강도 낮은 경우
- 모델 파라미터값의 함수- 정확도
6.4 Grid Search 모델 세부 튜닝
주어진 문제에 모델이 적합한지 측정할 수있는 성능 지표
OvA(One-versus-All) 방식 사용 다중분류로 확장
불균형한 데이터셋 :Imbalanced-learn
예. 스팸 필터링 , 부정 감지, 질병 차단
- 재현율 : 높은 양성 예측 정확도를 보여주지만 유용하지 않음
- 정밀도:
- 업샘플링: 소수 클래스의 샘플을 늘리는데 사용 (업샘플링)
- 다운샘플링: 다수 클래스의 샘플 삭제
- 인공적인 훈련 샘플 생성 : SMOTE(Synthetic Minority Over-sampling Technique)
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 목차
<머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 Python Machine Learning By Example, 2/E : Implement machine learning algorithms and techniques to build intelligent systems(Paperback, 2nd Edition)..
potato-potahto.tistory.com
Reference
'Data > ML' 카테고리의 다른 글
| 8. 감정분석 (0) | 2021.06.15 |
|---|---|
| 7. 앙상블 학습 (Ensemble Learning) (0) | 2021.06.14 |
| 5.차원축소를 이용한 데이터 압축 (0) | 2021.06.13 |
| 4. 데이터 전처리 (0) | 2021.06.12 |
| 3.사이킷런을 타고 떠나는 머신 러닝 분류 모델 투어 (0) | 2021.06.11 |